本文参考文件为:CFX黄皮书导读 ,交易转发中的带宽优化
[TOC]
第十章 激励机制
对于每一种数字货币,存在以下人群:
直接建设者:创始团队和基金、开发者、
系统维护者:大矿工、散户;
生态建设者:持币者、社区用户。
- 钱包、托管商、去中心化交易平台
公链一般通过通胀的方式间接对所有的持币用户收税,以此补贴给矿工来为网络提供数据安全性。对于一个公链生态,给矿工补贴多少才算合理值得思考。如果补贴太少,难以保障矿工的参与度和系统的安全性;如果补贴太多,难以保障生态开发者的积极性。
着重介绍 Conflux 网络的矿工费产生、计算与分配的原则,以及挖矿奖励以何种方式进行递减,何种情况下会没有矿工费等情况。
Conflux的创世通证总量是50亿CFX。16%给投资者+36%给研发+8%社区基金+40%生态基金(给DApp的开发者),都设置了2~4年的解锁年限。
| DeFi Coin | 出块大小 | 交易速度 | 确认速度 | 经济模型 | 价值 |
|---|---|---|---|---|---|
| 比特币 | 1MB | 每 10 分钟 3500 笔交易 | >=10分钟 | 发行总量限制在 2100 万,采用的是通缩的经济模型 | 18000美金 |
| ETH | 每秒 15-17 笔交易 | 通胀的经济模型,以定量的增发率给矿工提供持续激励。 | 620美金 | ||
| CFX | 200 KB | 在没有坏人攻击的情况下,5s 一个 4MB 大小的区块,确认时间约 8 分钟。在有 30% 算力攻击的情况下,确认时间约 16 分钟。? | 备注:秒级上链,分钟级确认。 |
10.1 以太坊无维护费
以太坊依然存在手续费过高的问题,限制了开发者和用户的进入。同时,用户仅通过一次性支付手续费就可以将交易数据存储在链上,而以太坊上的全节点要储存所有账本状态,状态储存没有上限,用户也无需支付维护费,对矿工占据存储资源的激励模式不具备可持续性。不仅如此,以太坊大部分状态空间都被无效的智能合约占据,不但浪费存储空间,也减慢了系统速度,造成了网络延迟。
10.2 比特币/ETH的矿工激励模型
POW 系统的主要维护者——矿工,主要负责验证并记录系统中的交易,是保障系统稳定的重要角色。
按照比特币的激励机制,矿工每挖出一个最长链上的区块,就可以获得一定数额的比特币作为区块奖励。最开始这个奖励数额是 50 BTC, 之后每挖出 21 万个区块,比特币的区块奖励就减半。截止 2020 年 5 月 12 日,比特币已经历了第三次区块奖励减半,目前比特币的区块奖励是 6.25 BTC。
除了区块奖励,比特币矿工的另一个收入来源是交易费。每个用户在发起一笔交易时,需要支付一笔交易费。每个比特币区块中所有的交易费会付给挖出这一区块的矿工。在比特币的设计中,早期的交易不多,区块奖励是矿工主要的收入来源;随着时间推移,当比特币的用户越来越多,区块奖励也经过多次减半后,交易费将取代区块奖励成为矿工收入的主要部分。例如,在比特币区块 500439 中,交易费超过 13 BTC,高于该区块的区块奖励 12.5 BTC。
2.ETH的奖励也是出块奖励(叔块)和交易费。
以太坊的基础区块奖励没有比特币的定期减半计划。在初始阶段,以太坊的基础区块奖励是 5 ETH。在 2017 年名为拜占庭的硬分叉中,649 号提案被激活,基础区块奖励调整为 3 ETH。随后,1234 号提案将基础奖励进一步降低至 2 ETH。
为了给智能合约消耗的计算资源定价,用户在以太坊中发起交易时,不直接指定交易费,而是指定一个交易费单价,被称为燃料价格(gas price)。交易实际执行时按照计算量的多寡消耗燃料,燃料用量乘以燃料价格就是以太坊最终向每笔交易收取的交易费。
CFX检测并惩罚疑似“未遂攻击”的行为
Conflux不希望看到,由于激励机制没有对未遂的攻击行为做出任何惩罚,导致矿工随意违反共识规则甚至尝试发起攻击。惩罚传播不及时的区块——无论这个区块是生成以后没有被及时广播,还是生成的时候故意无视了一部分已经收到的区块。
10.3 Conflux 的矿工奖励
包括区块奖励和交易奖励+存储维护奖励(存储押金的利息)
基础区块奖励的数值由 Conflux 系统生成的总区块数量确定。系统运行时间越长,基础区块奖励越低。
分叉攻击与自私挖矿在树图结构上无法区分,表现出来都是有一些区块似乎广播得特别慢,有很多光锥外区块。

我们通过实验验证了在攻击者进行分叉攻击时,区块奖励收益随藏块时间增加而受到的影响。在下图中,横轴代表了攻击者在这一攻击中的藏块时间,纵轴代表了攻击者“实际收益”与“诚实行为收益”的比值,四种颜色对应攻击者控制全网 10%, 20%, 30%, 40% 算力的情况。可以看出,随着藏块时间的增加,攻击者获得的区块奖励会随着藏块时间增加而迅速降低,最终在一分钟到一分半的时候降为 0。

10.4 存储抵押利息奖励
参考存储抵押利息奖励
在 Conflux 中,用户可以主动将代币以活期的方式存起来(Staking),并获得年化大约 4.08% 的利息。这些利息是通过增发来完成的。
利息的计算以区块为颗粒度。
具体来说,Conflux 每秒生成 2 个区块,每年生成大约 63072000 个区块。每个区块产生的利息就是
4% / 63072000。考虑上复利,一年的综合利率约为 4.08%。
哪些数据是收取存储费的?
对于存储数据,1 CFX/KB。存储押金的价格是 1/1024 CFX/byte。每个存储单元计 64 字节。除此之外,合约创建后,代码也要收存储押金。
如果一个交易在附言栏(input)部分填入了大量的数据,这个大交易会使区块丢失一些打包其他交易的机会,因为区块大小有上限。但在大约一天过后,交易本身会被全节点删除,只有档案节点可以查到。
因此,这些数据是不收取存储押金的,因为它对全节点存储空间的占用是短期的。或者可以理解成,在交易费中,已经涵盖了在未来一天时间内全节点的存储费用。如果一个智能合约维护了一个数组,并且在数组里存入了大量的数据。那么这些数据需要被所有节点永久地保存下来(除非被删除),以保证无论何时调用合约,合约都可以正常被执行。
每个 epoch 中所有产生的存储押金利息,将在同 epoch 的区块之间,以各区块的基础奖励为权重平分。也就是说,如果一个区块受到了来自光锥外区块的惩罚,这个惩罚同样会影响它第二部分存储抵押利息奖励的分配。
社区-生态治理模型
DAO(去中心化自治)治理,Conflux的社区成员锁定一点期限一定数量的token来获得vote。
投票权=锁定时长(季度结算)×通证数量×0.25
3月,6月和1年为限,分割锁定时长。
附录
11.1 Conflux 的 CVM 和 EVM 虚拟机层的主要区别
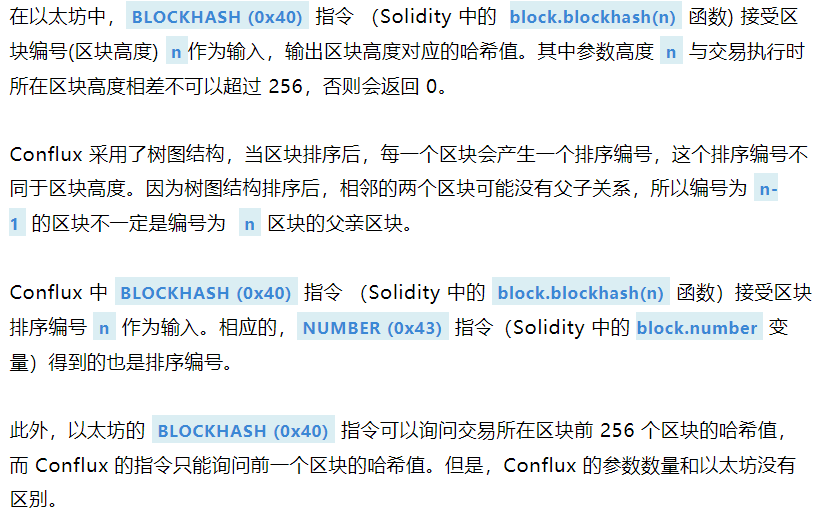
区块高度和区块哈希相关的指令
Conflux 采用了树图结构,当区块排序后,每一个区块会产生一个排序编号,这个排序编号不同于区块高度。因为树图结构排序后,相邻的两个区块可能没有父子关系,所以编号为 n-1`的区块不一定是编号为 ** n ** `区块的父亲区块。
交易中的信息填写
一般由RPC 和 SDK 会替开发者和用户做好这件事情。
- Chain ID: 区块链编号。规定可以执行这笔交易的区块链编号,避免有人将测试网的交易拿到主网上重放。目前,测试网的 Chain ID 是 1,主网的 Chain ID 是 2。这是主网地址:https://confluxscan.io/
Epoch 编号增长 100000 的时间在半天到几天不等;
Epoch Height: 交易执行时的(大概的)epoch。如果交易执行时实际的 Epoch 与交易填写的 Epoch Height 相差 100000 以上(Epoch 编号增长 100000 的时间在半天到几天不等),交易将执行失败。也就是说,过长时间未被打包的交易将无法执行。
合约代码上限
eum 网络中,每个区块能处理多少指令是有上限的,即我们所说的 Block Gas Limit。限制 Block Gas Limit 的主要初衷之一,是当它高于一个阈值之后,可能会造成 Ethereum FullNode 同步区块的速度赶不上区块生成速度的情况,导致网络逐渐不可用。
在 Ethereum 网络中,每个区块能处理多少指令是有上限的,即我们所说的 Block Gas Limit。限制 Block Gas Limit 的主要初衷之一,是当它高于一个阈值之后,可能会造成 Ethereum FullNode 同步区块的速度赶不上区块生成速度的情况,导致网络逐渐不可用。
EIP-1559 是由以太坊联合创始人 Vitalik Buterin 和 ethhub_io 创始人 Eric Conner 合作提出的以太坊交易费机制改进提案,其核心思路很简单——在网络交易需求量大的时候,增大 Block Gas Limit,在需求少的时候,减少 Block Gas Limit,让一段时间内的平均 Block Gas Limit 不变,但能动态应付短时的需求峰值。
Question
这里的增大,是指增大上限,让交易发起人的指令消耗得到满足?还是加大限制,本来网络就堵,你一个人就不要需求那么大了?
我想应该是后者。
在 EIP-1559 中,交易手续费被分为两部分,一部分为全网约定的基础手续费,一部分为用户自己指定的小费。当一个区块的 Block Gas Limit 的利用率高于 50% 时,基础手续费 Gas Price 会升高为原来的 112.5%;相反,如果利用率低于 50%,基础手续费 Gas Price 会降低为原来的 87.5%。
每一笔交易基础手续费的产生都是 Ethereum 生态繁荣的一部分,所有参与者应该共同享受这部分收益,所以在 EIP-1559 中,所有基础手续费都会直接烧毁,减少全网 ETH 供给量。由于基础手续费被烧掉会导致矿工没有意愿去打包交易,所有着急发送交易上链的用户,可以提升交易里的小费,激励矿工尽快打包自己的交易。
交易转发中的带宽优化
交易广播是在区块链上达成共识的第一步。每当用户发起一笔交易时,这笔交易从客户端程序出发,被发往一个或几个全节点。之后,全节点之间通过点对点网络将交易转发给各自的邻居节点,直到最终所有的全节点都收到这笔交易。
区块链的吞吐量越大则每个节点需要转发的交易数量也就越多。因此,在区块链的吞吐量和网络带宽处于相同的数量级时,交易转发过程的带宽利用率将直接影响了整个区块链系统最终的吞吐性能。
方案一:每当一个全节点收到一笔新的交易时,该全节点就将这笔交易发送给它的所有邻居节点。浪费
比特币的方案是,当一个比特币节点 A 第一次收到这笔交易时,它将这笔交易的哈希值(32字节)发送给所有的邻居节点(除了发给它交易的节点)。邻居节点 B 收到哈希值后查看自己已经收到的交易中有没有哈希值一样的。如果有,就说明 B 已经收到过这笔交易,不需要再接收一次;如果没有,B 就向 A 请求这笔交易的完整内容。
方案三:将 announcement 环节产生的数据发送量压缩至八分之一。
为了将 announcement 环节广播的交易哈希值与应用层面(钱包/智能合约)所使用的 32 字节交易哈希值区分,我们将应用层面交易的哈希值称为交易的 ID, 转发中 announcement 环节用到的短哈希值称为交易的 FID (Forwarding ID).
如果我们将 FID 设为 ID 值的前 4 个字节,就可以达到降低数据发送量的目标。
然而,更短的交易 FID 在节省带宽的同时也会带来安全性上的隐患。如果两笔不同的交易 Tx1 和 Tx2 有相同的交易 FID ,一个节点收到第一笔交易 Tx1 后,在邻居节点发来第二笔交易 Tx2 的 FID 时,会因为 FID 冲突误认为自己已经收到了这笔交易,从而不再请求 Tx2 的完整内容。这样将阻塞第二笔交易 Tx2 在网络中的广播。
假设交易的生成速率是每秒 6000 笔交易,每个全节点收到一笔交易 FID 时,会将它和过去 5 分钟内收到的 FID 对比,来判断是否请求这笔交易的完整内容。这样,一笔交易的 FID 和已经存在的交易 FID 冲突的概率是 6000 * 300 / 232,大约是 0.04 %。这意味着每秒平均有 2.4 笔交易会因为 FID 值冲突而无法广播。
虽然 0.04% 的冲突概率看似不是很高,但这只是没有攻击的正常情况。利用特定的攻击策略,一个攻击者可以阻塞任意一笔交易的广播,从而实现阻止特定交易的目的。
方案三的改进:
为了解决静态 FID 易被攻击阻塞的问题,我们将 FID 的取值由静态转变成动态的。因为 FID 只是在节点与节点之间转发交易时的临时取值,与共识逻辑无关也不需要被记录在区块链上,所以 FID 值没有必要是一个不变的数值。
每个节点在计算 FID 时,并不仅仅由交易的 ID (交易的 32 字节哈希值)计算,而是选择一个随机数 r,通过 ID 和 r 共同计算出一个 4 字节的 FID,并将r 与 FID一同发送。这样,当随机数 r 改变时,交易的 FID 也会随之发生改变,收到 FID 和 r 的节点需要根据 r 重新计算已有交易的 FID 来完成对比,并确定需要请求哪些 FID 对应的完整交易。因为一次转发的多笔交易可以共享同一个随机数 r, 所以这个随机数 r 几乎不会在带宽上带来额外的负担。
由于 r 的随机性,攻击者并不能预计一笔交易在每次转发时选择的 r 和由此算出的 FID 分别是多少,自然也就无法预先构造冲突的交易了。
这个设计的另一个好处是,即便节点 B 给节点 A 发送交易时发生了 FID 值冲突,导致某笔交易没有成功发送给节点 A,另一个节点 C 发送这笔交易给 A 时,大概率将采用不同的随机数 r 计算 FID,相当于增加了一次把这笔交易发给 A 的机会。
只要计算 FID 的过程足够随机(如使用伪随机函数),则 B 发送成功和 C 发送成功可看作是两个独立的事件。根据我们之前的计算,一笔交易因为 FID 值冲突而发送失败的概率是 0.04%,而节点 B 和 C 两次独立发送都失败的概率是 0.04% × 0.04%,失败率大大降低。
然而,从随机数计算 FID 的设计也有一个缺点:每当节点收到一个新的随机数 r 时,就要为所有已经收到的交易(根据上一期的假设,全节点会将过去 5 分钟内收到的 180 万条交易和刚刚收到的 FID 对比)重新算一遍 FID,这会带来了极大的计算负担。
这样,根据交易 ID 的前 3 字节,我们把所有的交易放在了 224 个“桶”里。每次一个节点收到其他节点发来的 FID 和 r 时,先根据 FID 的前 3 字节判断交易所在的桶,再将自己已经收到的,落在这个桶里交易根据 r 重新计算 FID 值并比对。
简单地计算可以发现,对于 180 万条随机生成的交易,平均每个桶里只有 0.1 笔交易,即使是含有交易最多的桶里也不会超过10 条。重新计算一个桶里交易的 FID 所需花费的成本远远低于重新计算所有交易的 FID。
在上面这个 3+1 动静结合的方案下,攻击者其实仍然可以重复类似的攻击策略。之前的攻击策略中,攻击者为每一个静态的 FID 准备一笔交易。在这一策略中,攻击者为每个桶预先准备一些交易。当受害者的交易出现后,攻击者在短时间内大量广播与受害者交易在同一个桶里的交易,就能够降低受害者交易被转发到其他节点的概率。即使同一笔交易每次转发时采用一个完全随机的动态字节,但是这个动态字节只有 256 种可能的取值,所以一个桶中的交易越多,冲突概率也会越高。
如果一个节点收到一个 FID 时,发现这个 FID 对应的桶里已经有不少于 10 条交易,就不再使用 FID 来判断,而是直接请求完整的 32 字节交易哈希值来对比是否接受过这笔交易。这样,攻击者就不能再通过制造冲突的 FID 来阻塞交易广播了,因为冲突过多的时候反而无法起到阻塞的作用。
这条额外的规则触发时会让交易转发退化到没有使用 FID 优化的情况。但是因为正常情况下每个桶里期望只有 0.1 笔交易,几乎不可能发生超过 10 笔交易落在同一个桶里的情况,所以这条额外的规则在系统没有遭到攻击时并不会被触发。而当系统真的遭到攻击的情况下,保护系统的安全性和稳定性才是最重要的,即便为此而降低系统的吞吐量也是可以接受的妥协。
跨链方案
实现资产的跨链交易
跨链原子交换:哈希时间内的合约锁定,并由交易双方在线完成交易。
跨链原子映射:将一条链上的资产锁定,1:1铸造等量的资产到另外一条链上。