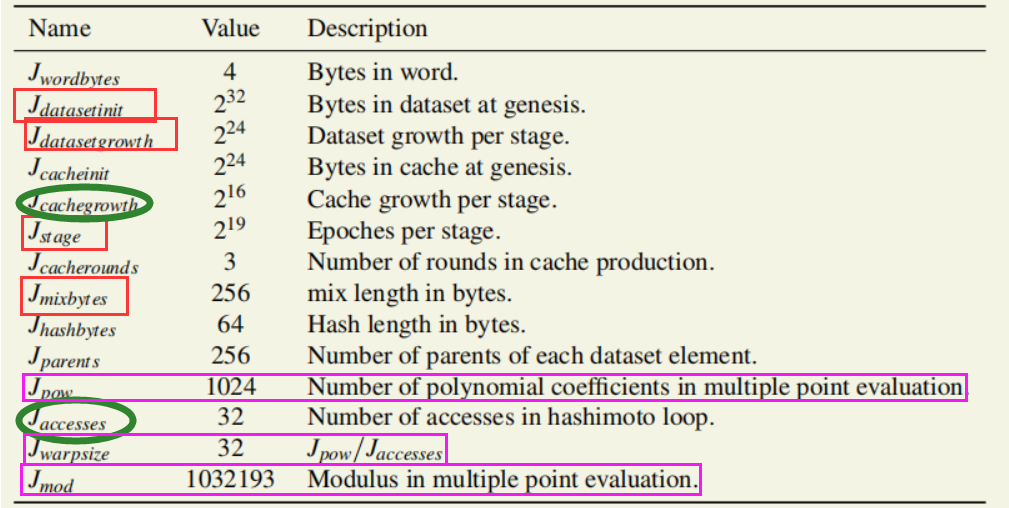
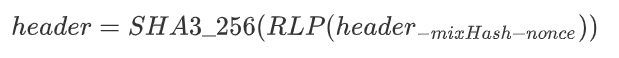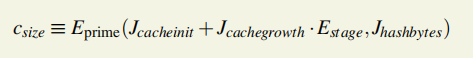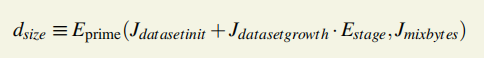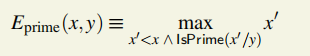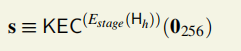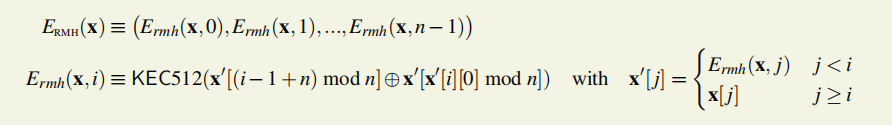WORD_BYTES = 4# bytes in word DATASET_BYTES_INIT = 2**30# bytes in dataset at genesis DATASET_BYTES_GROWTH = 2**23# dataset growth per epoch CACHE_BYTES_INIT = 2**24# bytes in cache at genesis CACHE_BYTES_GROWTH = 2**17# cache growth per epoch CACHE_MULTIPLIER=1024# Size of the DAG relative to the cache EPOCH_LENGTH = 30000# blocks per epoch MIX_BYTES = 128# width of mix HASH_BYTES = 64# hash length in bytes DATASET_PARENTS = 256# number of parents of each dataset element CACHE_ROUNDS = 3# number of rounds in cache production ACCESSES = 64# number of accesses in hashimoto loop
defmkcache(cache_size, seed): n = cache_size//HASH_BYTES
# Sequentially produce the initial dataset o = [sha3_512(seed)] for i inrange(1, n): o.append(sha3_512(o[-1]))
# Use a low-round version of randmemohash for _ inrange(CACHE_ROUNDS): for i inrange(n): v = o[i][0] % n o[i] = sha3_512(map(xor, o[(i-1+n) % n], o[v]))
return o
输出是一组524288个字(64字节值),即32MB。
5.Full dataset的生成
1 2 3 4 5 6 7 8 9 10 11 12
defcalc_dataset_item(cache, i): n = len(cache) r = HASH_BYTES // WORD_BYTES#16 # initialize the mix mix = copy.copy(cache[i % n])#浅拷贝,cache和mix同步变化 mix[0] ^= i#64字节的异或 mix = sha3_512(mix) # fnv it with a lot of random cache nodes based on i for j inrange(DATASET_PARENTS):#256轮 cache_index = fnv(i ^ j, mix[j % r]) mix = map(fnv, mix, cache[cache_index % n]) return sha3_512(mix)
合并了来自256个伪随机选择的缓存节点的数据,并对其进行哈希处理以得到数据集中的一项。
1 2
defcalc_dataset(full_size, cache): return [calc_dataset_item(cache, i) for i inrange(full_size // HASH_BYTES)]
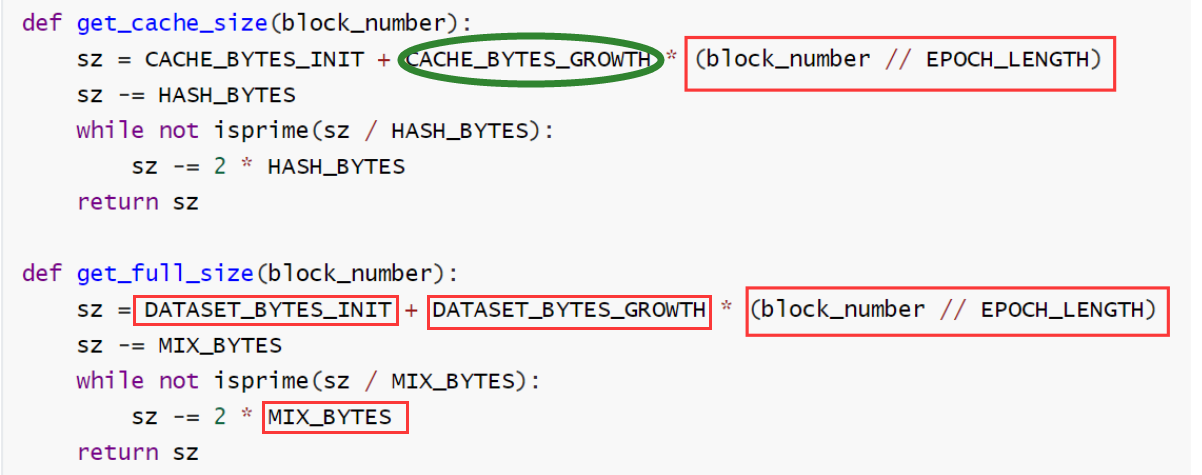
defmkcache(cache_size, seed): n = cache_size//HASH_BYTES
# 1.初始数据集大小即为cache_size,64个字节为一个单位进行生成 o = [KEC512(seed)] for i inrange(1, n): o.append(KEC512(o[-1]))#序列化的生成这么大的空间,之后再填充
# 2.Use a low-round version of randmemohash,进行3轮内存困难hash函数 for _ inrange(CACHE_ROUNDS):#3轮 for i inrange(n):#缓存以64字节为1单位,共有n个64字节 v = o[i][0] % n#o[i]的前4个字节/第一个字,o[i]这一项共有16个字 o[i] = KEC512(map(xor, o[(i-1+n) % n], o[v]))#每一项的第一个字和前一项异或得到当前项
return o
第2步图解如下:
输出的缓存大小是32M,猜测是为下一轮增加缓存准备的。
5.Full dataset的生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defcalc_dataset_item(cache, i):#i是512bit值 n = len(cache) r = HASH_BYTES // WORD_BYTES#16 # initialize the mix mix = copy.copy(cache[i % n])#浅拷贝,cache和mix同步变化 mix[0] ^= i#64字节的异或 mix = KEC512(mix) # fnv it with a lot of random cache nodes based on i for j inrange(DATASET_PARENTS):#256轮 cache_index = fnv(i ^ j, mix[j % r]) mix = map(fnv, mix, cache[cache_index % n]) return KEC512(mix)
defcalc_dataset(full_size, cache): return [calc_dataset_item(cache, i) for i inrange(full_size // HASH_BYTES)]