[TOC]
0.上周讨论会总结的新问题
- conflux的throughput大概是6400tps(4M/2.5s的配置,40Mbps的带宽下)
5.76G/h, 5.68 分钟确认一个块
- 私有挖矿问题(为什么攻击者把块公开给一个人后,所有人都会知道这个块),分布式同步假设
conflux是如何解决存储大这个矛盾的
conflux为什么创建块和确认块都快
- 为什么parent edge和ref edge可以保证共识不可逆
- ghost和ghast协议具体介绍
pivot chain具体是怎么确认的,学长说是入度大小,而不是以该节点为根的子树的整个树大小。
每个epoch内的happens-before是怎么排序的,例如下图中的E这个epoch内排序后为什么是DFE而不是FDE。√
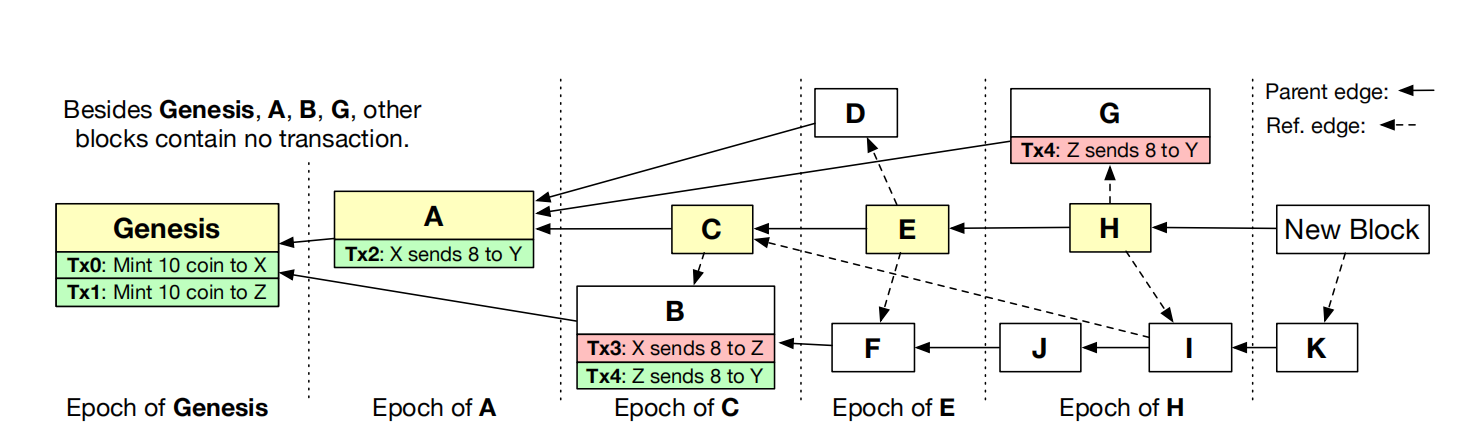
conflux的安全性等价于bitcoin的证明√
conflux如何防止分叉的√
以上问题都比对区块链中的机制并举例进行讨论
0.1 为什么parent edge和ref edge可以保证共识不可逆
- Parent edge ,一种voting relationship
- Ref Edge,一种 generated-before relationship
Parental tree,所有的parent edges组成一个parental tree。
根据GHOST规则,Conflux从Parental tree中选择一个pivot tree。
0.2 什么是GHOST协议?
减少分叉,尽快招安成为长链。
0.3 Pivot Chain的选择
the child block with the largest subtree
0.4根据Pivot Chain得到Total Order
3.2 Conflux中的假设
3.2.1 Safety and Liveness Properties
对于我们关心的程序性质, 将可以分为两类:
- Safety Properties, 在程序运行中不会进入非预期的状态(如非法调用参数, 数组下标越界等运行错误).
- Liveness Properties, 在程序运行中预期状态一定会到达(如停机, 获取资源请求一定有返回结果等等).
3.2.2 分布式同步假设
参考,分布式共识的工作原理
底层八卦网络为所有诚实节点提供分布式同步通讯;
没有分布式系统,也就不可能有区块链;区块链就是一种新型的分布式系统。
3.2.2.1 分布式系统的定义
一个分布式系统包括一组相互独立的进程(比如计算机),它们互相传递消息并进行协作以完成一个共同的任务.
分布式系统四大特性
并发、缺乏全局时钟、单点可能出错、消息传递。
- 崩溃错误:组件没有预警就停止工作(比如计算机崩溃了)。
- 遗漏错误:组件发了一个消息但没有被别的节点收到(比如这条消息丢包了)。
- 拜占庭错误:恶意参与者造成的错误。组件不按既定规则工作。这种类型的错误在可控环境中不会发生(比如谷歌和亚马逊的数据中心),因为一般认为那种环境中系统里不会发生恶意行为。与之相反,拜占庭错误会发生在所谓的“敌对环境”中。简单来说,当一组去中心化的独立参与者作为节点加入某个分布式网络后,这些参与者可以完全不按既定规则行动,也就是说它们可以恶意地更改消息、拦截消息或者根本不发送任何消息。
同步系统和异步系统之间的区别
- 同步通信情况下,消息会在固定时间范围内发送。
- 异步通信情况下,无法保证消息的传递。
3.2.2.2 共识问题与FLP不可能定理
分布式计算最常见形式称作复制状态机。它是一个分布式计算机的集合,这些计算机都有相同初值。每一次状态的转变方式、下个状态是什么,都由相关的进程决定。所谓“达成共识”,意思是全体计算机都同意某个输出的值。也意味着让系统中每一台计算机的事务日志保持一致
1.共识算法=选举(elect)+投票(vote)+决定(decide)。三个角色,提案者、接受者、学习者。
2.只要能满足以下条件,我们就说某算法可以实现分布式共识:
- Agreement(一致性) :所有非故障节点,都会选择相同的输出值。
- Termination(可终止性):所有非故障节点,最终都选定了某些输出值,不再反悔。
面对异步通信环境,因为我们无法假设一个最大的消息传递时间,想要达成 termination 条件是非常困难的,也就是说每个非故障节点对输出值选择会迟疑不决。这也就是大家熟知的“ FLP 不可能性 ”。
1985年,研究员 Fischer、Lynch 和 Paterson (FLP)在他们的论文《Impossibility of Distributed Consensus with One Faulty Process》中描述了为什么在异步通信环境下,单个进程故障也会导致共识无法达成。
简单来说,因为进程可能在任何时间出错,所以也有可能发生在正好会影响共识达成的时间点。
避开 FLP 不可能性问题:
- 使用同步性假设
- 使用非确定性机制
3.2.2.3 synchronus假设
因为消息异步传递,所以并非总能在固定时间达成共识。引入超时(timeout)的概念规避 FLP 不可能问题。如果在确认下个值的过程没有进展,我们会等到超时,然后重新进行共识的步骤。
虽然在 Paxos 算法中没有明确的定义超时,但在实际部署时,发生超时之后选择新的提案者是满足 termination 的必要条件。否则,我们无法保证接收者会输出下一个值,这会导致系统停止运转。
拜占庭+异步环境困局
攻击者可以不按协议要求,把自己生成的块的parent and reference edge指向任意已存在的块。但是,攻击者无法修改与已生成块相关连的边,即使该块是由攻击者本人生成的。它的密码学机理是什么?
1.私有挖矿问题
陈块检测机制保证攻击者不能永久保留自己的块
- 比特币引入了
网络调整时间,对等实体的时间戳中间值。
如果新块的时间戳早于前11个块的中间时间戳,或者新块的时间戳比网络调整时间晚两个小时,则新块将被标记为无效。
- Conflux,1.根据块的生成速率同步调整无效条件。新的无效条件块数=11*conflux造块速率/Bitcoin造块速率。2.不删除无效块。只是在选举主链时计算子树块数目时不计入这些块。
- 基本原理是,只要无效块不再影响已经稳定的epoch的分区方案,就可以安全地将其包含在将来的时期中,处理该块中的事务。???
- 比特币引入了
分布式同步假设保证攻击者把块公开给一个诚实节点后,所有人都会知道这个块
2.存储问题
1.Block Header
Conflux修改Bitcoin中的块头结构,对每个ref edge增加一个32byte的块头哈希。开销可忽略?实验结果证明每个块小于960字节,也就是说每个块顶多有30个参考边?。这些ref edge的哈希也要作为难题的一部分。
1 | hash(ref edge) |
将以验证的块广播到共识层。
2.引导一个节点
单向同步,从peer下载全部block到全新的node。
1 | #增加的四个消息类型 |
3.GHOST rule
在以太坊出现之前就有,以太坊对它做了修改。 使用的基于链的中本聪共识协议,出块速度是BItcoin的40倍。
10多秒的出块时间,分叉可能性增多。
mining centralization 和bias
GHOST rule V1.0
限制只能包含两个叔父区块,uncle block得到7/8的奖励被招安,包含叔父区块的块得到1/32奖励。这样以太坊的钱就比较值钱。
- 当有3个叔父区块时,有一个叔父区块将无法被包含;
- 挖出下一个块了,才得知有叔父区块存在
- 商业竞争角度,有的矿池损失1/32的奖励,而故意不包含叔父区块
GHOST rule V2.0
记录叔父区块的权利下移。
那么我可以在解决难题比较简单的时候,不断产生叔父区块。为了解决这个问题,规定了最大可及该叔父区块的代数。
叔父可以隔很多代,最大代数为7,算上侄子一共8个节点。对于叔父区块,奖励隔代递减,但是对于侄子奖励始终是1/32。
即7代以内有共同的主线。鼓励出现分叉后,及早合并
block reward ;3个以太币
gas fee tx fee;动态奖励,
Conflux相较如何?
4.Confirm时间
获得不可逆信心需要的等待时间,攻击者掌握算力和用户愿意承受风险三者之间的关系。
5.Conflux随网络带宽和节点数增长的扩展情况
6.泊松过程模拟挖矿
7.BItcoin与以太坊、Conflux
以太坊是一个交易驱动的状态机,执行智能合约的,发起合约要支付gas fee,执行合约的矿工会获得gas fee。
以太坊中并没有规定出块奖励逐渐递减,比特币这样规定是人为制造稀缺性,从而成为数字黄金。以太坊的奖励是和挖矿难度相关的,难度炸弹和奖励持平。
以太币比作gas是不完全准确的,gas只是转移了账户。叔父区块获得block reward,但是它记录的交易不会被执行,因为叔父区块和主链上的交易可能冲突。
所以侄子区块不执行叔父区块里的交易,也不检查叔父区块里交易的合法性。只检查叔父区块的header里是否解决了难题。
7.2.若是叔父区块后面跟着一串区块(即在分叉链)
相当于招安一个队伍
但是这样会降低叔父区块的成本,因为攻击者自己造链也有补偿了。
所以ETH中只有分叉后的第一个区块有奖励
7.3 Conflux的时空消耗
基于DAG的方法所产生的的时间消耗相比PoW可忽略,空间消耗每个块最大960Bytes<典型几M的块大小。
7.3.1 Throughput
10k个全节点分别运行2个小时,通过控制变量,研究块大小和产生块的速率对快利用率的影响。
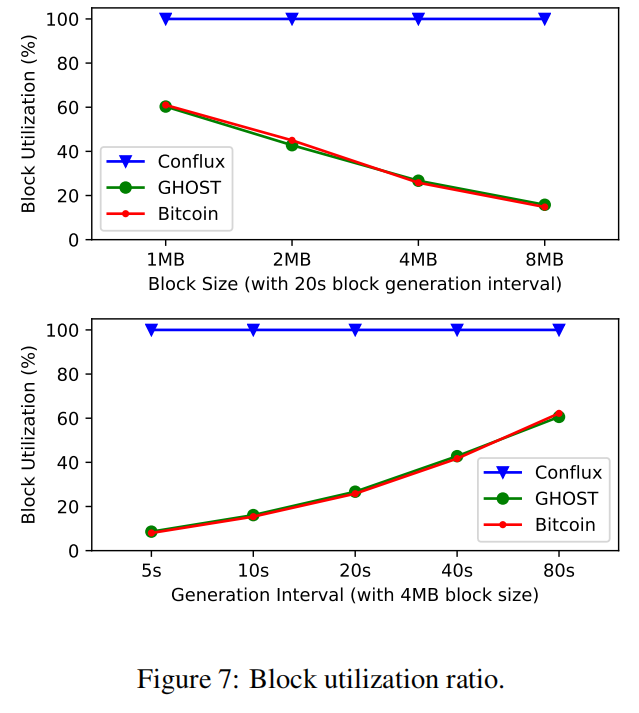
由于Conflux与出块时间和块大小无关,所以其仅受每个单独节点的处理能力的限制。
而GHOST和Bitcoin随着块大小和造块速度的提高,分叉机会变多,块利用率降低。只有8% and 8.6%在商定的链条上。
- GHOST和Bitcoin的分叉中的块将不包括在结果总顺序中,生成这些块的资源就浪费了。
- Conflux能够处理所有块,效率/吞吐量就提升了
7.3.2 Confirmation Time
为了块的前缀总排序不变从而无法逆转交易所需要等待的时间。所以当块产生速率提高时,成链速度提高,确认速率也就提高了。但是,随着块生成速率接近单个节点的处理能力,这种影响会减弱,因为频繁的并发块和分叉会减慢节点的确认速度。
等待时间越长,风险越低。
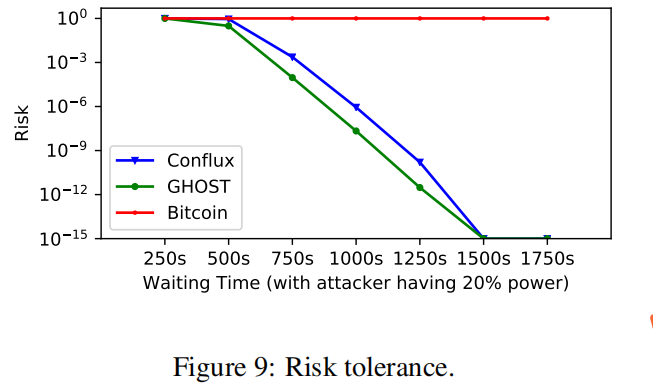
4M/10s下, Conflux依然能在16.8 minutes获得confifidence 99.99%
攻击者算力越高,需要等待更长的时间已达到相同的风险忍受预期。这个风险是随着时间指数下降的。
但是为什么在攻击者有20%算力的时候,Bitcoin的风险始终是一呢?
除了这三种配置, 1M/20s, 2M/20s, and 4M/80s,其他配置下Bitcoin的最长链太短了,无法抵抗20%的算力攻击?
7.3.3 可扩展性
节点数倍增时,传播时延线性增加,带宽增加,速度增加。
8.SPECTRE,PHANTOM Liveness Attack
8.1 SPECTRE
非传递性的部分顺序
而Conflux为支持智能合约这样的应用,对所有交易总排序。
- pivot chain是通过parental tree的parent edge获得的,因此Conflux安全性基于GHOST
- Inclusive blockchains以一致的方式包含链下交易。
包容性区块链协议中的主链是其DAG中定义的不可扩展路径,因此无法将GHOST直接应用于包容性区块链协议。
8.2 PHANTOM Liveness Attack
PHANTOM为本地块DAG找到一个近似的k集群解决方案,以减少潜在的恶意块。
First Phase
染色,red or blue
这个过程仅看论文附录介绍,看不明白,论文只染蓝色。
8.2.2 Liveness Attack
| 诚实节点 | 恶意节点 | |
|---|---|---|
| 区块 | B b1,b2,b3 | A a1,a2,a3 |
| 网络 | ||
a1被通过,而a1属于anti(b2),所以b2被kick out。
8.3 Nakamoto Consensus
权威链记录总排序的、不可逆的交易,分支链中的块和交易都抛弃。
而Conflux分支链上的块也有贡献。
8.4Consortium consensus
减少对Nakamoto共识协议的使用来加速,比如Bitcoin-NG选举Leader负责提交交易。
BFT 协议(集体签名?)
以上协议都是要选举一个特定的群组来确认交易顺序,可以根据他们在系统中的股份或外部信任层次来选择组。
Conflux比Consortium好的两个方面
1.所有人参加交易顺序的确定
2.可以容忍半数节点恶意,而BFT最多1/3
3.BFT类协议在选举团换届前必须排出总顺序,而COnflux延缓排序
Conflux在吞吐量和延迟上选择了高吞吐量。吞吐率和确认时间是此消彼长的?
对于大小矿工的公平性上
大矿工不能再通过分叉链使小矿工的块无效。
只要块生成速率稳定,Consensus共识算法可以和PoS互补。
附录














