反向传播的一个比方,以猜数字为例,B手中有一张数字牌让A猜,首先A将随意给出一个数字,B反馈给A是大了还是小了,然后A经过修改,再次给出一个数字,B再反馈给A是否正确以及大小关系,经过数次猜测和反馈,最后得到正确答案。
Logistic regression逻辑回归
二分类算法;
- image—>matrices—>feature vector—>{0,1};
- many images—>X—>Y;
1.Notation
1 | #m_train、m_test |
2.激活函数
使模型可以拟合非线形函数。
Sigmoid激活函数
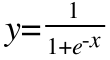

tanh
过原点的单调递增曲线,值域为[-1,1]

和Sigmoid对比:
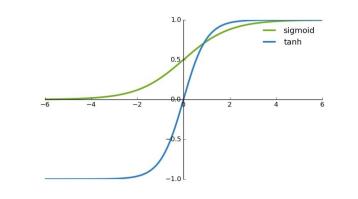
Relu激活函数
整流线性单元
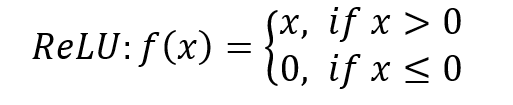
线性、非饱和,可以克服学习过程中的梯度消失问题,加快训练速度。
SoftMax
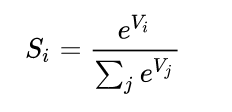
SoftMax Loss的缺点:
1、随着分类数目的增大,分类层的线性变化矩阵参数也随着增大;
2、针对封闭集分类问题,学习到的特征是可分离的,不适用于开放集这种所学特征没有区分性的分类问题。 ——> SM-SoftMax
2.2 不常见的激活函数
Elu
指数线性单元
f(x)=alpha * (exp(x)-1) ,x<0
1 | keras.activations.elu(x, alpha=1.0)#alpha一个标量,表示负数部分的斜率。 |
SElu
SELU 等同于:scale * elu(x, alpha)
可伸缩的指数线性单元(SELU)。
ThresholdedReLU
带阈值的修正线性单元。
形式: f(x) = x for x > theta, f(x) = 0 otherwise.
PReLU
参数化的 ReLU
1 | #形式: f(x) = alpha * x for x < 0, f(x) = x for x >= 0, |
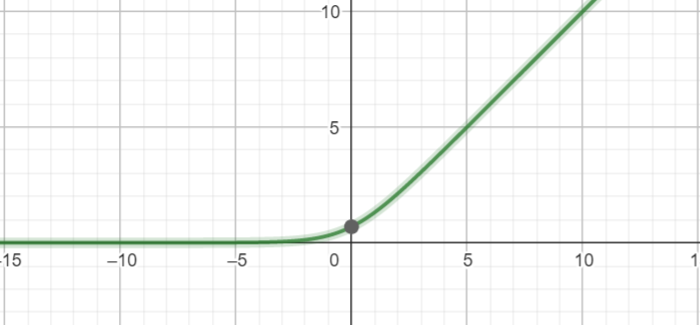
softplus
f(x)= log(exp(x) + 1)
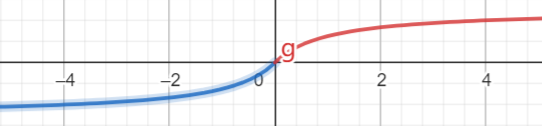
softsign
f(x)= x / (abs(x) + 1)
Hard sigmoid 激活:
计算速度比 sigmoid 激活函数更快。
- 如果
x < -2.5,返回 0。 - 如果
x > 2.5,返回 1。 - 如果
-2.5 <= x <= 2.5,返回0.2 * x + 0.5。

3.学习器
基于训练数据迭代的更新神经网络权重。
3.1 梯度下降过程
随机梯度下降保持单一的学习率更新所有的权重,学习率在训练过程中并不会改变。
在用梯度下降法做参数更新的时候,模型学习的速度取决于两个值:
一、学习率;
二、偏导值。
3.2 Adam学习器
Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
学习率:反向传播时修改权重的比率。
Softmax运算:
将输出映射到(0,1),成为一个个的概率值,累加为1。选取输出结点时,选择概率最大的结点作为预测目标。
重训练
更新: