数据转换
数据进行初步预处理后(清洗[异常值处理,噪声的去除]),将数据变为规格化的形式。
并在归一化和标准化后,进行组合或者转换扩充出新的特征。
- 1.分类问题中的,对类别编码为数值表示(哑编码)。
- 哑编码: onehot编码+00…0(全0的编码)
- 2.连续数据转化为离散值,通过分段。
3.文本数据 wordbag(词袋法),word2vec(体现词的上下文结构,word—>一串数字)或者TF-IDF(词频*逆文档频率)
- (IDF给常见的词较小的权重,帮助获得关键信息)
- TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言(语料库)中的出现次数成反比。
- 通过计算文章中各个词的TF-IDF,降序排序,排在最前面的几个词,就是该文章的关键词。
- 4.图像数据 (颜色空间,灰度处理,几何变化, haar特征(通过特征原型在图像窗口上的滑动得到的矩形特征的值),图像增强)
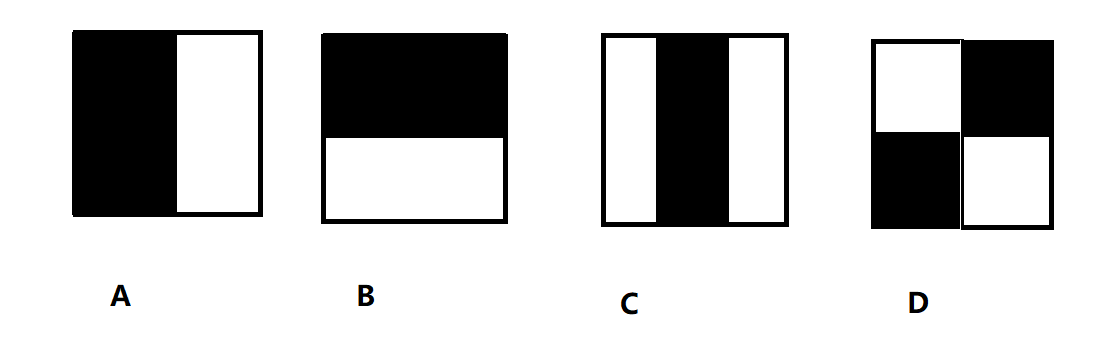
haar特征的四种形式的特征模板,边缘特征、线性特征、中心特征和对角线特征。
积分图
AdaBoost算法
特征选择
带来的好处
1.避免维度爆炸,
2.减少训练时间
3.简化模型,使得模型更容易被解释???
4.提升模型的泛化性(关键特征的样本是可以迁移的),避免过拟合。
1.过滤法(Filter):
选择特征的时候是独立的,与模型本身无关。
- 通过评估每个特征和目标属性之间的相关性
- 皮尔逊相关系数
- 卡方系数
- 互信息
- 过滤法的局限性:倾向于选择冗余的变量(互相依赖的一圈特征都会被选择出来),因为它们没有考虑特征之间的关系。
2.包装器(wapper)
用于评估特征的组合。使用一个预测模型来对特征子集进行评分。
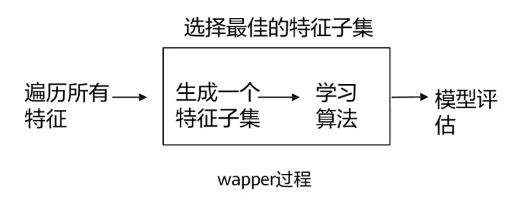
常见方法:特征递归消除法
局限性:包装器方法会为每个特征子集训练一个新模型,所以它的计算量非常大。
- 它会为特定模型选出最好的特征集,导致模型的泛化能力不足。
3.嵌入法(Embedded)
将特征选择作为模型构建的一部分。