现有攻击方法
对抗性攻击
借助子模型模仿(偷取)目标模型生成对抗样本(具有可迁移性,使本地子模型分类错误的样本也可以适用于目标模型。)进行攻击。
原理:
训练得到的模型边界与真实的决策边界不一致。
(因为用于训练的原始样本集不可能将所有情况都涵盖。)

模型训练的边界与真实决策边界之间的空间就是对抗样本的空间。根据特征的梯度方向对样本特征进行改变,使得样本逐渐绕过边界。
缺陷:需要攻击者在目标模型上进行大量的查询来获得大量反馈。
防御:
- 微笑着面对它(主动防御)。训练阶段就使用对抗样本来训练模型,让模型更加健壮。
- 请求帮助(被动防御)。正式运行后,构建辅助网络,预测输入样本是对抗样本的概率。
投毒攻击
分类:针对目标的攻击、无差别投毒攻击、后门。
- 无差别投毒攻击:旨在破坏模型的可用性
- 目标性投毒:旨在通过投毒使得某一个或者某一类样本能躲避模型的检测。
原理:
无差别投毒攻击:伪造错误数据或者修改数据标签后,模型抓取到的数据是虚假的或者错误的,用人话说就是模型的世界观被歪曲或者颠倒了。
- 缺陷:需要控制样本标签;模型整个不可用了,易被发现
针对性投毒攻击:通过给样本添加目标标签对应的特征,让它绕过模型的边界。
- 缺陷:针对特定的样本,不能通用。
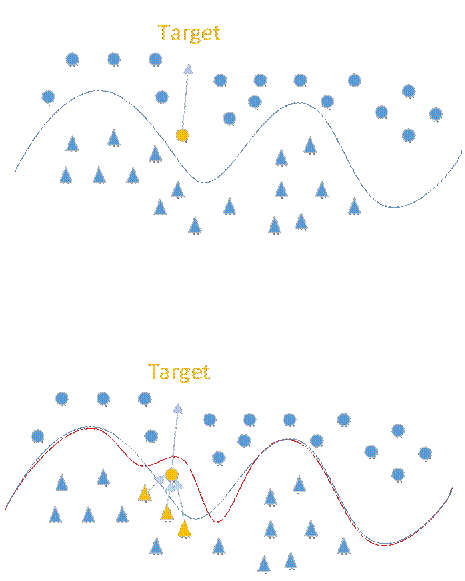
后门:让模型有后门。对于干净的数据集进行分类,只有遇到特定标记的样本时才会触发后门。
- 缺陷:需要控制样本标签;
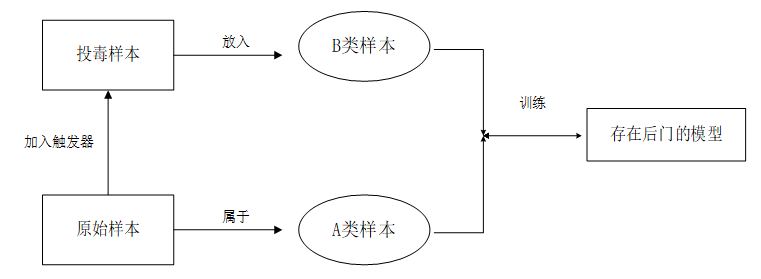
防御:
与对抗性攻击的防御类似。训练之前预先过滤,检测剔除可疑样本;