1 | D:. |
第三章-目标文件格式
俞甲子等,《程序员的自我修养——链接、装载与库》,北京:电子工业出版社,2009年6月第2版。
不放过任何一个字节。
利用工具:gcc、readelf、objdump、size,cl
strace ./run跟踪程序的运行
objdump
1 | objdump -j .got -h add.so 看一下.got的段信息. |
gcc命令
1 | -E 预处理、 |
readelf
1 | -hlS |
3.1 目标文件的格式
目标文件:源代码编译后但还未链接的那些中间文件(.o或者.obj)
静态链接库:把很多目标文件捆绑形成一个文件,再加上一些索引,可以简单理解为一个包含很多目标文件的文件包。
1 | file xxx.so |
表明该文件的兼容性,采用了Unix System V的格式规范,即COFF文件。
注:Unix最早的可执行文件格式为a.out,无法应对共享库等概念,所以设计了COFF来解决它。
COFF的贡献:目标文件里引入了段机制,不同文件可以有不同数量和不同类型的段(Section节或者Segment段);定义了调试数据格式。
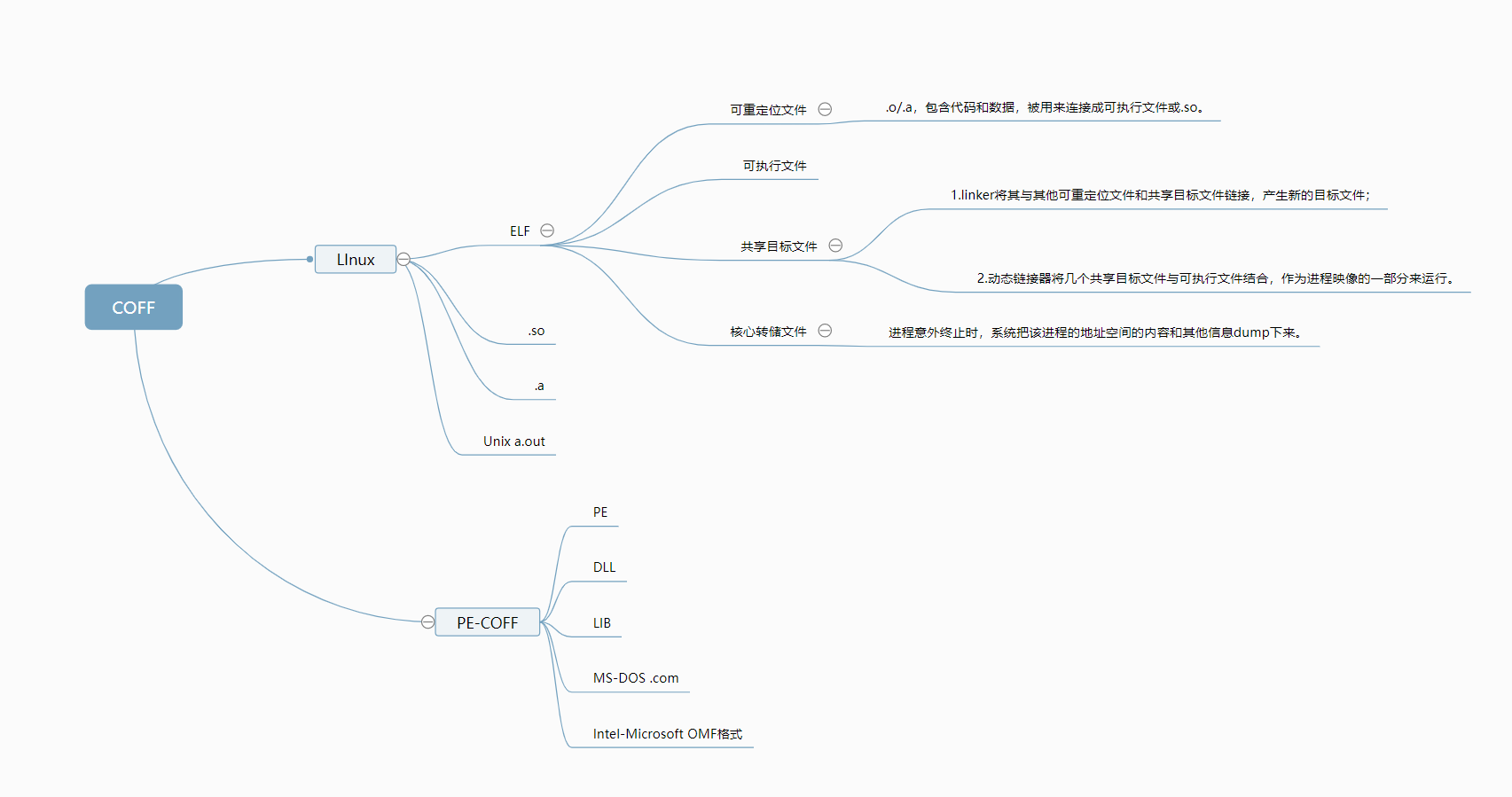
3.2为什么分段
指令和数据分段的好处:
1、给程序指令区域单独设置可读权限,防止程序被改写。
2、利用局部性原理提高缓存的命中率。现代CPU缓存也设计成数据缓存和指令缓存分离。
3、在内存中有多个程序副本时,通过内存共享,节省内存空间。只读数据(指令;图像、文本资源)可以共享;而每个副本进程的数据区域不一样,是进程私有的,属于Private Bytes。
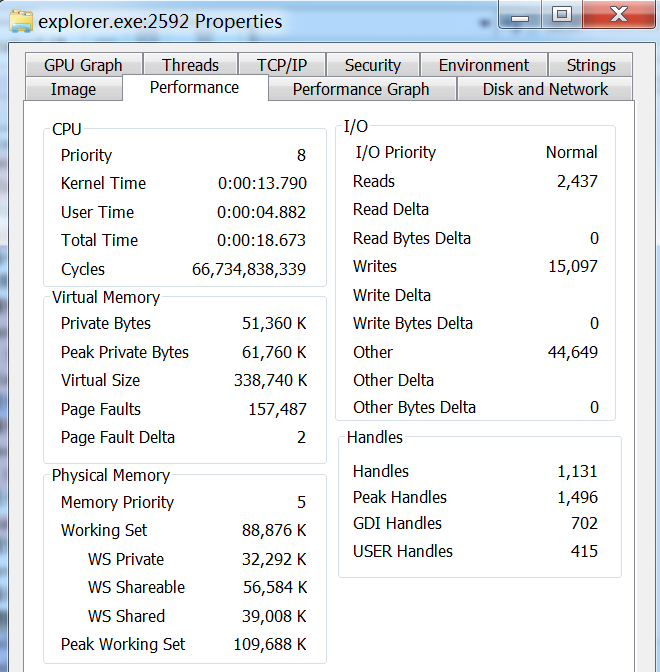
如图所示,Win7的exploer.exe在运行中,此刻占据的总虚存为338 740KB,它的私有数据部分占了51 360 KB,即共享部分数据占了287 380KB,也就是280多MB的空间,极大的节省了内存空间。
3.3 段概述
ELF Header,描述整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接还是可执行文件(给出入口地址)、目标硬件和目标操作系统,还包括一个段表 Section Table:一个描述各个段在文件中偏移位置及段的属性的数组。
| | |
| ————————- | —————————————————————————————— |
| .bss | 为节省存储空间,只记录未初始化数据预留的空间大小,而不存储其内容,因为其默认全部为0. |
| .data | 初始化的全局变量和局部静态变量 |
| .text、.code | 代码段 |
| .rodata、.rodata1 | 只读数据段,比如字符串常量、全局const变量 |
| .comment | 存放编译器版本信息,比如字符串:”GCC:(GNU) 4.2.0” |
| .note | 额外的编译器信息,程序公司名、发布版本号等 |
| .debug | 调试信息 |
| .line | 调试时的行号表,源代码行号与编译后指令的对应表 |
| .eh_frame | 存储异常处理框架(Exception Handling Frame)的相关信息。包括异常处理函数的调用关系、异常处理函数的地址、堆栈展开信息等。 |
| SHT | 表示 “Section Header Table |
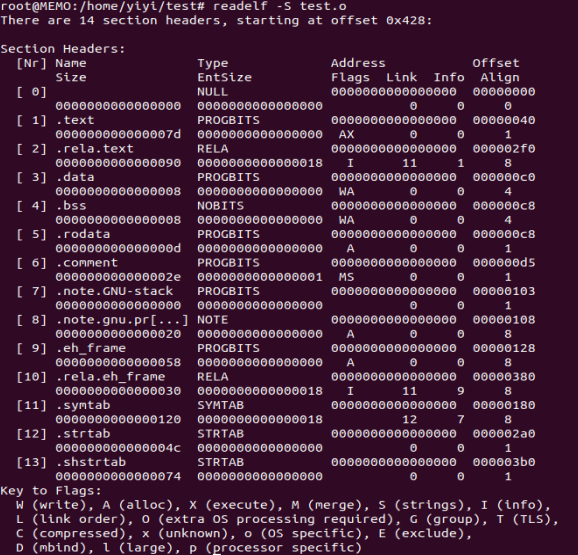
其他段 .got和.plt
| .dynamic | 动态链接信息 |
|---|---|
| .hash | 符号哈希表 |
| .strtab | String Table,字符串表 |
| .symtab | Symbol Table,符号表 |
| .shstrtab | Section Header String table,段名表,集中管理段名称。不存储用户自定义的字符串,而是存储与 ELF 文件结构相关的字符串 |
| .plt\.got | (Procedure Linkage Table,过程链接表),是动态链接的跳转表,用于延时加载; 全局入口表 Global Offset Table |
| .init,.fini | 程序初始化与终结代码段 |
.表示这些段名由系统保留,应用程序自定义段名不能加.,否则容易跟系统保留段名冲突。
一个elf文件中可以有多个.text的段。
一些已遗弃的段名:.sdata、.tdata、.sbss .lit4 .lit8 .reginfo .gptab .liblist .conflict
BSS段
Block Started by Symbol Table ,最初是美航符号汇编程序(1950s)的一个伪指令,被IBM保留并引用到Fortran 汇编器,用于定义符号并且为该符号预留给定数量的未初始化内存空间。
因为bss段没有内容,所以它在文件中不占据空间;但是,程序运行时,要占内存空间。
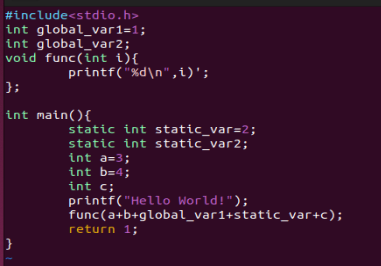
借助size命令,查看代码段和数据段长度。

借助objdump查看各段基本信息,-x查看详细信息。
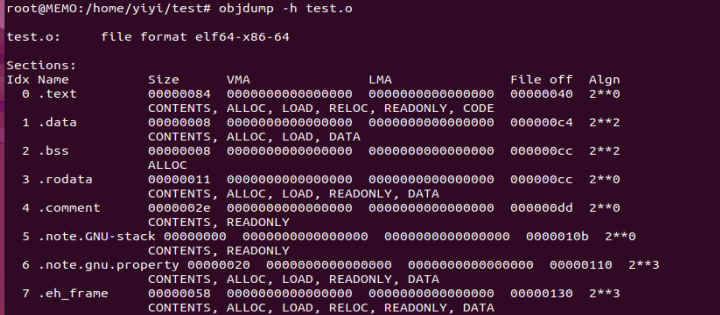
1 | VMA Virtual Memory Address 运行地址,PC指针所指,程序真正运行的地址空间 |
解释:一个初始化的全局变量+一个初始化的局部静态变量,所以.data的Size为8;同理,.bss大小为8;因为两个printf里共有13+4共17个字符(每个字符串尾还有一个\0),所以这里的rodata大小为0x11.
各个段属性的第二行中,CONTENTS表示该段在文件中存在,可以看到BSS段没有CONTENTS,它在ELF文件中不存在内容。
测试
1 | static int x1=0;//则x1应该放入.bss段里,因为未初始化的值就是0,放入.bss可以节省空间。 |
3.5 链接的接口-符号
链接如同拼积木,目标文件B引用A中定义的函数和变量,需要其具备独特的名字。
链接过程中,我们将函数和变量称为符号;其名称称为符号名。
PE/COFF
俞甲子等,《程序员的自我修养——链接、装载与库》,北京:电子工业出版社,2009年6月第2版。
1.5 程序的分段和分页
解决三个问题:1.内存隔离。2.空间利用。3.重定位。
本质上是增加了一个中间层,即虚存,这样就可以避免在编写程序时还要考虑详细的地址分配问题了。为了内存隔离,分段;为了细粒度的空间利用,分页。
CPU->虚拟地址—>MMU(Memory Management Unit,内存管理单元)—>物理地址。
2.1 构建过程
预编译:.cpp/.cxx.,.hpp——>.i,.ii,处理所有的”#”预编译命令并递归插入和展开宏命令,删除注释,加入行号和文件名标识,保留#pragma编译器指令。
编译:gcc -S/cc1 hello.c -o hello.s。完成词法分析和语法分析,生成中间代码。
1 | #include <...> search starts here: |
汇编:gcc -c /as hello.s -o hello.o。把汇编符号翻译为机器码。
链接:ld,最终确定各个符号的绝对地址,完成对指令引用的符号地址的校正,需要一大堆文件。
2.2 编译原理概述
词法分析,Scanner—>Tokens,识别记号,同时叫标识符放到符号表(lex)。
语法分析,Parser—>Syntax tree,关于编译器的编译器(yacc)。
语义分析:Semantic Analyzer—>Commented Syntax Tree(注释语法树),只能分析静态语义:声明、类型匹配转换(在编译器可以确定的语义,其他的等待程序运行(除0异常)时才能确定)
中间代码生成:使得编译器可以拆分为前后端。非常接近目标代码,但是跟目标机器与运行时环境无关。不包含数据尺寸、地址和寄存器名字。
目标代码生成与优化:生成器和优化器。
1 | LEA,基址比例变址寻址(Load Effective Address),进行地址的计算后将算得的结果放入存储中,不会把结果地址的内存数据实际加载到寄存器里。用于高效地进行一些复杂的地址计算,例如数组索引、数据结构访问等,而无需实际读写内存 |
2.3 链接器年龄比编译器更长
纸带编程时,一些跳转都是绝对地址,需要人为计算,一旦指令间增删其他指令,所有目标地址都要重新人工计算(重定位,Relocation,每个要被修正的地方叫一个重定位入口,Relocation Entry),一条纸带上的指令很麻烦,多条纸带间更是灾难。
引入符号(对函数和变量位置的助记符),计算符号地址的过程让汇编器自动完成,方便程序的模块化。
程序之间的接口就是这些符号,类似于拼图,我少这一部分,你恰好多这一部分,每个模块放到合适的位置,就是一幅完整的有意义的图。
2.4 静态链接是什么玩意?
详细介绍在第4章。
链接过程包括:地址和空间分配、Symbol Resolution(符号决议:静态链接,绑定:动态链接)和重定位。
库:常用的代码编译成目标文件存放,例如运行时库。
5.2一些历史
DEC(Degital Equipment Corp.)被 康柏电脑 收购, 康柏电脑02年又被惠普(1939)收购。DEC推出的VAX/VMS(Virtual Address eXtension/System) ,是一个最先使用权限管理和容错机制的多任务OS, 提供高性能、可靠性和安全性 。微软开发Win NT时,最初成员来自于DEC的VAX/VMS小组,所以Windows的PE格式来自于DEC的VAX/VMS上的COFF(Common Object File Format)文件格式。
贝尔实验室 (Bell Telephone Laboratories, 1925 ) —> 肖克利半导体实验室(Shockley Semiconductor Laboratory,1955) —> 仙童半导体(Fairchild Semiconductor,1957) —>AMD(1968),Intel(1968) —>Microsoft(操作系统,1975)。
SGI(Silicon Graphics, Inc.,1982) —>NVIDA(正在收购ARM(移动处理器),1993), Netscape (1994年,开源了 Netscape Navigator(打不过微软IE) ,发展成为 Mozilla Firefox 。
Google (创建者为Stanford University博士,PageRank算法: Google搜索引擎的核心, 通过链接关系评估网页的重要性 , 1998 )
思路:链接多的代码块,也可以权重传递和赋予它高的权重值。
COFF:VC++产生的目标文件格式。
PE:Win平台下的可执行文件格式,和ELF都是基于段的相同结构, 是COFF的一种扩展。对于64位系统,将PE中的32位字段改为64字段,叫做PE32+。
映像文件Image File:因为PE文件在装载时会被映射到进程的虚拟空间中运行,它是进程虚拟空间的映像,所以PE可执行文件又可称为映像文件。
SMP与多核
服务器要的是 并发吞吐 ,要CPU核数、要线程数、要大的L2/L3缓存。
而PC要的是单核频率。
截至2023年5月12日,至强的处理器基准频率基本在4GHz以下, 酷睿i9-13900KS 睿频最高为6GHz(受生产工艺影响)。出于性能需求发展出多处理器,SMP(symmetrical)是其中的常见形式,由于成本高,通过共用缓存,SMP发展成为多核处理器。
段名
段名只具有提示作用,没有实际意义。不同编译器产生的段名不同,VC++用’.code’和’.data’。
使用链接脚本来控制link时,段名含义一般是固定的。
自定义段
1 | //GCC,扩展属性,将变量或者函数放入自定义段中 |
使用VS Command Prompt,编译:
1 | #编译,不调用链接器,禁用Microsoft C/C++语法扩展,生成标准的C/C++目标文件 |
Microsoft C/C++语法扩展,编译器会自动定义__STDC__这个宏。
利用VS目标文件查看工具查看COFF格式或PE格式,详细/简介。
1 | dumpbin [/all,summary] hw2.obj >hw2_section.txt |
C runtime library (UCRT)
Android_Rev00
恶意检测2023年论文摘要汇
[1] 针对在程序功能无关区域添加修改的一类对抗样本攻击, 利用模型解释技术提取端到端恶意代码检测模型的决策依据作为特征, 进而通过异常检测方法准确识别对抗样本. 该方法作为恶意代码检测模型的附加模块, 不需要对原有模型做修改,
[2]建立了一种多尺度卷积核混合的卷积神经网络架构,以提高恶意代码识别能力. 该模型运用具有捷径(shortcut)结构的深度大内核卷积和标准小内 核卷积相结合的混合卷积核(Mixed Kernels,MK)模块,以提高模型准确率;在此基础上,通过多尺度内核融合(Multiscale Kernel Fusion,MKF),以降低模型参数量;再结合特征重组(feature shuffle)操作,实现优化特征通信???,在不增加模 型参数量的前提下提升了分类精度 。
[3]设计 APT 恶意 软件基因模型和基因相似度检测算法构建恶意行为基因库,
[4] . 针对目前研究仅着眼于提升模型分类准确率而忽略了恶意代码检测的时效性 。将多尺度恶意 代码特征融合与通道注意力机制结合,增强关键特征表达,并使用数据增强技术改善数据集类别不平衡问题 ,检测速度快。
[5]生成概率 CFG,其中顶点代表操作码,操作码之间的边代表这些操作码在文件中出现的概率。。。。
[6]可视化方法生成的恶意软件图像并没有保留语义和统计属性,尺寸小且统一。 本文给出了提取内容和填充模式的定义,以表征恶意软件可视化任务的关键因素,并提出了一种新的基于汇编指令和马尔可夫传递矩阵的恶意软件可视化方法来表征恶意软件。 因此,提出了一种基于三通道可视化和深度学习(MCTVD)的恶意软件分类方法。。。。
[7]通过实施 CNN 模型和迁移学习 (TL,MobileNetV2 和 ResNet-50 模型) 进行恶意软件分类的深度学习,以克服基于 DL 的恶意软件检测模型中的常见问题,包括过度拟合、高资源消耗和无法检测混淆的恶意软件。本文提出的模型检测混淆的能力强。。。。
[8]提出了提高特征表示质量的两种新机制。一是通过重新解释user-defined function calls的操作码序列来捕获这些函数调用的语义;二是将文字信息整合到函数调用图FCG的嵌入中,以实现更好的判别能力。在静态检测的背景下,通过采用所提出的两种机制,五个广泛采用的分类器对恶意软件家族分类的准确率平均提高了 2%。。。。(表示)
[9]
[1] 田志成, 张伟哲, 乔延臣, 等. 基于模型解释的 PE 文件对抗性恶意代码检测[J]. 软件学报, 2023, 34(4): 1926-1943.
[2] 张丹丹, 宋亚飞, 刘曙. MalMKNet:一种用于恶意代码分类的多尺度卷积神经网络[J]. 电子学报, DOI: 10.12263/DZXB.20221069.
[3]陈伟翔, 任怡彤, 肖岩军, 等. 面向 APT 家族分析的攻击路径预测方法研究[J]. Journal of Cyber Security 信息安全学报, 2023, 8(1).
[4] 王硕, 王坚, 王亚男, 等. 一种基于特征融合的恶意代码快速检测方法[J]. 电子学报, 2023, 51(1): 57-66.
[5] shah, I.A., Mehmood, A., Khan, A.N. et al. HeuCrip: a malware detection approach for internet of battlefield things. Cluster Comput 26, 977–992 (2023). https://doi.org/10.1007/s10586-022-03618-y
[6] Deng H, Guo C, Shen G, et al. MCTVD: A malware classification method based on three-channel visualization and deep learning[J]. Computers & Security, 2023, 126: 103084.
[7] Habibi O, Chemmakha M, Lazaar M. Performance Evaluation of CNN and Pre-trained Models for Malware Classification[J]. Arabian Journal for Science and Engineering, 2023: 1-15.
[8] Wu C Y, Ban T, Cheng S M, et al. IoT malware classification based on reinterpreted function-call graphs[J]. Computers & Security, 2023, 125: 103060.
[9] Malhotra V, Potika K, Stamp M. A Comparison of Graph Neural Networks for Malware Classification[J]. arXiv preprint arXiv:2303.12812, 2023.
https://arxiv.org/pdf/2303.12812
[10] Chaganti R, Ravi V, Pham T D. A multi-view feature fusion approach for effective malware classification using Deep Learning[J]. Journal of Information Security and Applications, 2023, 72: 103402.
[11] 利用节表的注入欺骗分类模型。da Silva A A, Pamplona Segundo M. On deceiving malware classification with section injection[J]. Machine Learning and Knowledge Extraction, 2023, 5(1): 144-168.
https://www.mdpi.com/2504-4990/5/1/9
[12]
Ravi V, Alazab M. Attention‐based convolutional neural network deep learning approach for robust malware classification[J]. Computational Intelligence, 2023, 39(1): 145-168.
[13]动态权重值的联邦学习分类安卓恶意软件方法
Chaudhuri A, Nandi A, Pradhan B. A Dynamic Weighted Federated Learning for Android Malware Classification[M]//Soft Computing: Theories and Applications: Proceedings of SoCTA 2022. Singapore: Springer Nature Singapore, 2023: 147-159.
https://arxiv.org/pdf/2211.12874
[14]增强勒索软件分类,通过多阶段特征提取和数据不平衡的校正。
Onwuegbuche F C, Delia A. Enhancing Ransomware Classification with Multi-Stage Feature Selection and Data Imbalance Correction[J].
[15]
[16]
[17]
[18]
[19]
[20]
TEB-PEB-SEH
去混淆工具使用
使用下面这条命令快速去混淆。
Get-Content .\Demo\DBOdemo*.ps1 | Measure-RvoObfuscation -Verbose -OutputToDisk
1 | Import-Module .\Revoke-Obfuscation.psd1 |
1.伪装vc++5.0代码:
PUSH EBP
MOV EBP,ESP
PUSH -1
push 111111 -___
PUSH 111111 -/ 在这段代码中类似这样的操作数可以乱填
MOV EAX,DWORD PTR FS:[0]
PUSH EAX
MOV DWORD PTR FS:[0],ESP
ADD ESP,-6C
PUSH EBX
PUSH ESI
PUSH EDI
nop
jmp 原入口地址
2.胡乱跳转代码:
push ebp
mov ebp,esp
inc ecx
push edx
ADD ESP,-6C
nop
pop edx
dec ecx
pop ebp
ADD ESP,6C
inc ecx
loop somewhere /跳转到上面那段代码地址去!
somewhere:
nop /“胡乱”跳转的开始…
jmp 下一个jmp的地址 /在附近随意跳
jmp … /…
jmp 原入口地址 /跳到原始oep
3.伪装c++代码:
push eax
mov ebp,esp
push -1
push 111111
push 111111
mov eax,fs:[0]
push eax
mov fs:[0],esp
pop eax
mov fs:[0],eax
pop eax
pop eax
pop eax
pop eax
mov ebp,eax
nop
nop
jmp 原入口地址
4.伪装Microsoft Visual C++ 6.0代码:
PUSH -1
PUSH 0
PUSH 0
MOV EAX,DWORD PTR FS:[0]
PUSH EAX
MOV DWORD PTR FS:[0],ESP
SUB ESP,1
PUSH EBX
PUSH ESI
PUSH EDI
POP EAX
POP EAX
nop
POP EAX
nop
ADD ESP,1
POP EAX
MOV DWORD PTR FS:[0],EAX
POP EAX
POP EAX
nop
POP EAX
nop
POP EAX
MOV EBP,EAX
JMP 原入口地址
5.伪装防杀精灵一号防杀代码:
push ebp
mov ebp,esp
push -1
push 666666
push 888888
mov eax,dword ptr fs:[0]
nop
mov dword ptr fs:[0],esp
nop
mov dword ptr fs:[0],eax
pop eax
pop eax
pop eax
pop eax
mov ebp,eax
jmp 原入口地址
6.伪装防杀精灵二号防杀代码:
push ebp
mov ebp,esp
push -1
push 0
push 0
mov eax,dword ptr fs:[0]
push eax
mov dword ptr fs:[0],esp
sub esp,68
push ebx
push esi
push edi
pop eax
pop eax
pop eax
add esp,68
pop eax
mov dword ptr fs:[0],eax
pop eax
pop eax
pop eax
pop eax
mov ebp,eax
jmp 原入口地址
7.伪装木马彩衣(无限复活袍)代码:
PUSH EBP
MOV EBP,ESP
PUSH -1
push 415448 -___
PUSH 4021A8 -/ 在这段代码中类似这样的操作数可以乱填
MOV EAX,DWORD PTR FS:[0]
PUSH EAX
MOV DWORD PTR FS:[0],ESP
ADD ESP,-6C
PUSH EBX
PUSH ESI
PUSH EDI
ADD BYTE PTR DS:[EAX],AL /这条指令可以不要!
jo 原入口地址
jno 原入口地址
call 下一地址
8.伪装木马彩衣(虾米披风)代码:
push ebp
nop
nop
mov ebp,esp
inc ecx
nop
push edx
nop
nop
pop edx
nop
pop ebp
inc ecx
loop somewhere /跳转到下面那段代码地址去!
someshere:
nop /“胡乱”跳转的开始…
jmp 下一个jmp的地址 /在附近随意跳
jmp … /…
jmp 原入口的地址 /跳到原始oep
9.伪装花花添加器(神话)代码:—————-根据C++改
nop
nop
nop
mov ebp,esp
push -1
push 111111
push 222222
mov eax,dword ptr fs:[0]
push eax
mov dword ptr fs:[0],esp
pop eax
mov dword ptr fs:[0],eax
pop eax
pop eax
pop eax
pop eax
mov ebp,eax
mov eax,原入口地址
push eax
retn
10.伪装花花添加器(无极)代码:
nop
mov ebp, esp
push -1
push 0A2C2A
push 0D9038
mov eax, fs:[0]
push eax
mov fs:[0], esp
pop eax
mov fs:[0], eax
pop eax
pop eax
pop eax
pop eax
mov ebp, eax
mov eax, 原入口地址
jmp eax
11.伪装花花添加器(金刚)代码:————根据VC++5.0改
nop
nop
mov ebp, esp
push -1
push 415448
push 4021A8
mov eax, fs:[0]
push eax
mov fs:[0], esp
add esp, -6C
push ebx
push esi
push edi
add [eax], al
mov eax,原入口地址
jmp eax
12.伪装花花添加器(杀破浪)代码:
nop
mov ebp, esp
push -1
push 0
push 0
mov eax, fs:[0]
push eax
mov fs:[0], esp
sub esp, 68
push ebx
push esi
push edi
pop eax
pop eax
pop eax
add esp, 68
pop eax
mov fs:[0], eax
pop eax
pop eax
pop eax
pop eax
mov ebp, eax
mov eax, 原入口地址
jmp eax
12.伪装花花添加器(痴情大圣)代码:
nop
……….省略N行nop
nop
push ebp
mov ebp, esp
add esp, -0C
add esp, 0C
mov eax, 原入口地址
push eax
retn
13.伪装花花添加器(如果*爱)代码:
nop
……..省略N行nop
nop
push ebp
mov ebp, esp
inc ecx
push edx
nop
pop edx
dec ecx
pop ebp
inc ecx
mov eax, 原入口地址
jmp eax
14.伪装PEtite 2.2 -> Ian Luck代码:
mov eax,0040E000
push 004153F3
push dword ptr fs:[0]
mov dword ptr fs:[0],esp
pushfw
pushad
push eax
xor ebx,ebx
pop eax
popad
popfw
pop dword ptr fs:[0]
pop eax
jmp 原入口地址 '执行到程序的原有OEP
15.无效PE文件代码:
push ebp
mov ebp,esp
inc ecx
push edx
nop
pop edx
dec ecx
pop ebp
inc ecx
MOV DWORD PTR FS:[0],EAX \
POP EAX |
POP EAX \
MOV DWORD PTR FS:[0],EAX |(注意了。。花指令)
POP EAX /
POP EAX |
MOV DWORD PTR FS:[0],EAX /
loop 原入口地址
16.伪装防杀精灵终极防杀代码:
push ebp
mov ebp,esp
add esp,-0C
add esp,0C
push eax
jmp 原入口地址
17.伪装木马彩衣(金色鱼锦衣)花代码
push ebp
mov ebp,esp
add esp,-0C
add esp,0C
mov eax,原入口地址
push eax
retn
18.
在mov ebp,eax
后面加上
PUSH EAX
POP EAX
19.伪装UPX花指令代码:
pushad
mov esi,m.0044D000
lea edi,dword ptr ds:[esi+FFFB4000]
push edi
or ebp,FFFFFFFF
jmp short m.00477F2A
20.
push ebp
mov ebp,esp
inc ecx
push edx
pop edx
dec ecx
pop ebp
inc ecx
jmp 原入口
21、
push ebp
nop
nop
mov ebp,esp
inc ecx
nop
push edx
nop
nop
pop edx
nop
pop ebp
inc ecx
loop A1地址
nop
nop
A1:push ebp
mov ebp,esp
jo 原入口
jno 原入口
【深层】伪装 WCRT Library (Visual C++) DLL Method 1 -> Jibz
黑吧代码 + 汇编代码:
使用黑吧粘贴以下代码:
55 8B EC 83 7D 0C 01 75 41 A1 C0 30 00 10 85 C0 74 0A FF D0 85 C0 75 04 6A FE EB 17 68 0C 30 00 10 68 08 30 00 10 E8 89 00 00 00 85 C0 59 59 74 08 6A FD FF 15 08 20 00 10 68 04 30 00 10 68 00 30 00 10 E8 52 00 00 00 59 59
粘贴完毕后,再添加2行汇编语句:
jmp 原入口地址 '执行到程序的原有OEP
retn 0C
发布几个不常见的花指令
B1 01 mov cl,1
2C 90 sub al,90
95 xchg eax,ebp
4D dec ebp
65:42 inc edx
40 inc eax
20C4 and ah,al
8350 06 6E adc dword ptr ds:[eax+6],6E
226A E4 and ch,byte ptr ds:[edx-1C]
E8 B15FBC5B call 入口点
55 push ebp
8BEC mov ebp,esp
51 push ecx
53 push ebx
8BD8 mov ebx,eax
8BC3 mov eax,ebx
04 9F add al,9F
2C 1A sub al,1A
73 03 jnb 入口点
JMP SHORT test.00414FB5 (EB 01)
NOP
JMP SHORT test.00414FB8 (EB 01)
NOP
JMP SHORT test.00414FBB (EB 01)
NOP
JMP test. (EB 01)
90=c4
PUSH EBP
MOVE EBP,ESP
inc ecx
push eax
pop eax
push edx
pop edx
dec ecx
sub eax,-2
ADD ESP,68
DEC eax
DEC eax
SUB ESP,68
JPE 入口
JPO 入口
NOP:这个指令代表“无操作”,通常被用作占位符或在程序中创建延迟。
LEA:这个指令代表“加载有效地址”,将某个值的地址加载到一个寄存器中,而不是加载这个值本身。
TEB
(Thread Environment Block,线程环境块)
| 偏移 000 004 008 00C 010 014 018 020 024 02C 030 |
说明 指向SEH链指针 线程堆栈顶部 线程堆栈底部 SubSystemTib FiberData ArbitraryUserPointer FS段寄存器在内存中的镜像 进程PID 线程ID 指向线程局部存储指针 PEB结构地址(进程结构) |
|---|---|
| 034 | 上个错误号 |
异常处理的优先级
- VEH 向量化异常处理 VectoredExceptionHandler
- SEH 结构化异常处理
- UEF UnhandledExceptionFilter
- VCH VectoredContinueHandler
借助遗传算法的语义搜索高效小样本学习
- Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Wang Yanggang, Haiyu Li, and Zhilin Yang. 2022. GPS: Genetic Prompt Search for Efficient Few-Shot Learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8162–8171, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
背景
用自然语言指令设置提示词,可以提高零样本设置中大型语言模型的任务性能。当前工作通过手动重写或基于梯度的调整来改进此类提示词。 然而,
手动重写非常耗时并且需要主观解释,
而基于梯度的调整对于大型模型的计算要求极高,并且需要完全访问模型权重,这对于基于 API 的模型可能不可用。
基于提示词的方法有利于小样本泛化,但是之前的都是手动设置,与之前的T0等方法不同,本文将各种来源的提示词作为种子,用遗传算法去进行提示词搜索,无须参数、无须梯度。
术语介绍
intrinsic dimension(本征维): 在多维信号的信号处理中,信号的本征维描述了生成信号的良好近似需要多少变量。
Ablation Study(消融实验): 在深度学习论文中,ablation study往往是在论文最终提出的模型上,减少一些改进特征(如减少几层网络等),以验证相应改进特征的必要性。
LM-BFF 5:: better few-shot fine-tuning of language models ,更好的适合小样本微调的语言模型。
DINO[22]:通过指令获得数据集的方法,Datasets from Instructions
T0:多任务encoder-decoder模型,针对不同下游任务,人为设计不同的提示词预训练后获得。
T5LM-XXL :XXL(11B)级参数规模的T5语言模型,
soft prompts和hard prompts: 模板的制作分为手工创建模板和自动化生成模板,而自动化生成模板又分为离散提示(又叫做硬提示)和连续提示(又叫做软提示)
以下均为需要微调参数的方法
BBT(Black-Box Tuning): 无梯度的微调方法,搜索连续空间中的最佳软提示词嵌入,而不是搜索离散的文本提示词。
MT(Model Tuning):在每个任务上对整个预训练语言模型进行微调的通用范式
PT(Prompt Tuning):预训练模型被冻结,只训练额外的连续软提示词的梯度引导的微调方法
无须微调参数的方法
ICL(In-Context Learning):上下文学习,大规模预训练模型进行小样本学习的通用方法。
由标注的样本和手动模板组成的范例被用来帮助模型理解test tasks的含义。
缺陷:需要人工提供手动提示词,对标记数据敏感,表现不稳定。
GRIPS( Gradient-free Instructional Prompt Search) :无梯度指令提示搜索,基于编辑的优化提示词搜索方法,主要用于简单的基于编辑的操作(例如增、删、交换、释义)
提示词重新生成方法
- BT:回译(back translation)。将提示词从英语翻译到其他 11 种语言,然后将它们翻译回英语。包括中文、日语、韩语、法语、西班牙语、意大利语、俄语、德语、阿拉伯语、希腊语、粤语,
- 完形填空(cloze)。利用LM-BFF[5]里的模板生成方法,使用T5(transformer)文本到文本预训练模型生成模板。对每个输入样例及其表达器(verbalizer)用占位符作为前缀和后缀生成模板,让T5去补全这些占位符。采用波束搜索(beam search)生成多个候选提示词。与论文[5]不同的是,本文的方法里是没有参数更新的,所以完型填空的效果并不好。所以本文中,使用人工提示词作为初始模板,用占位符代替一些随机的标记,然后让T5填空。选出在校验集(Ddev)时平均结果最好的提示词。
- SC:续写句子(sentence continuation)。采用和论文[22]中一样的根据指令生成数据集方法,采用模板“Write two sentences that mean the same thing. Sentence 1: Manual Prompt, Sentence 2:” 交给预训练模型去续写。采用了GPT2-XL (1.5B)和 T5LM-XXL (11B)作为提示词生成模型。
这些方法不需要人工定义编辑规则,而且生成的提示词语义流畅。
提示词打分
Close: 按照[5]里的方法,用校验集(D_dev)上的平均对数打分;
BT和SC:不适用平均对数,采用校验集(D_dev)上的准确率评价。
创新点:提示词遗传搜索算法
离散的词空间中找到高表现的硬提示词。

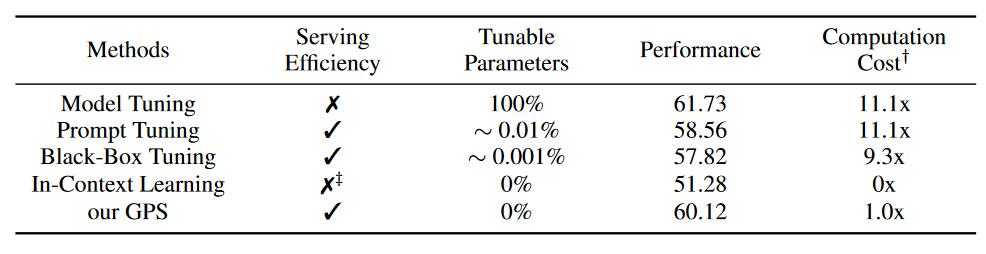
Table4 五种小样本学习方法在四个评价指标上的比较
这里的代价消耗是训练和提示词搜索的联合损失。
MT缺乏服务效率,因为保存MT需要对于每个任务都保存整个模型,造成巨大的存储开销。所有参数都需要调整,其使用的Adam等优化器要求存储额外的动量和方差项。
PT和BBT只需要调整提示词嵌入层。
ICL使用很长的序列长度来串联例子,推理昂贵,尤其是在范例数目多的时候。那为什么这里的代价只是1x???
可以看到,本文提出的方法GPS提供Serving Effiency、不需要参数更新、极大的减少了计算代价,还能取得接近于整个模型调优的效果。获得了60.12的准确率。
实验设置
数据集(NLP的)
T0语言模型的10个测试任务
自然语言推理任务(natural language inference):ANLI R1, ANLI R2, ANLI R3, CB, RTE
共指解析(coreference resolution):WSC, Winogrande
- 语句补全(sentence completion):COPA, HellaSwag
- 词义消歧(word sense disambiguation):WiC
| 方法 | 参数设置 |
|---|---|
| PT | Adafactor Optimizer,lr=0.05 |
| MT | Adafactor Optimizer,,lr=5e-5=0.00005 |
| BBT | 本征维度=500,pop size=20,使用交叉熵损失; 软提示词标记数量为1 or 50时结果最好 |
| ICL | 每个task随机从训练集挑2个样本 |
| GRIPS | 复用arXiv:2203.07281.里的超参数,将初始提示词换成T0的 |
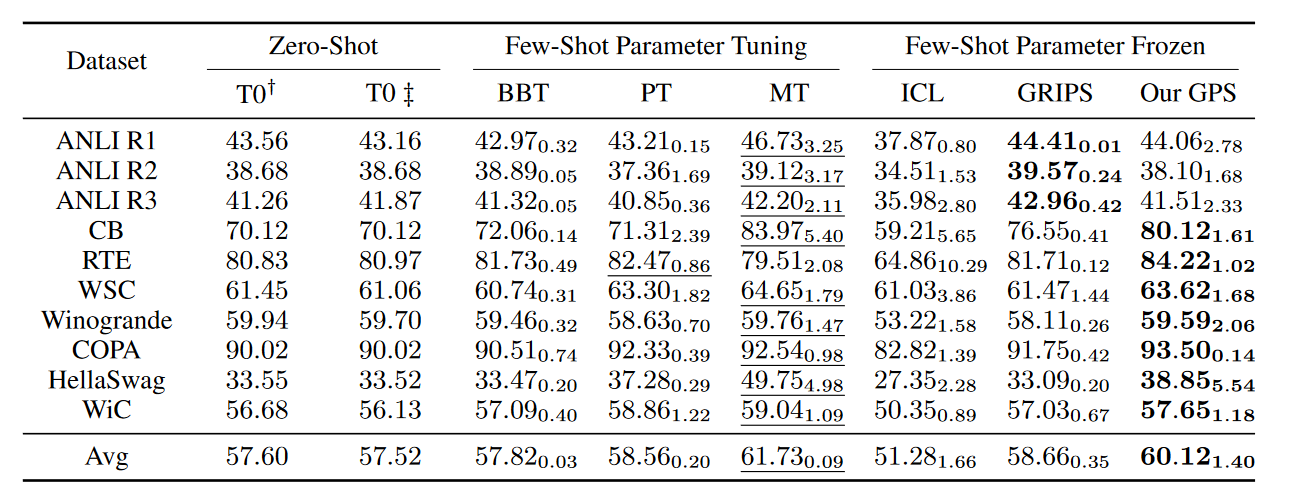
T0、BBT、PT、MT采用相同的人工提示词集,GRIPS和GPS自己搜索提示词。
实验结果是三种不同的数据划分方式的平均结果,脚注是一种方法在一个数据集的三种数据划分下的标准差。
划线部分给出了小样本学习下参数微调得到的最好结果,加粗部分给出了参数冻结方法的最好结果。

Table3 GPS产生的提示词的解释
>
我的未来工作
GPT-3表明,在超大规模预训练语言模型上使用提示词进行小样本学习效果良好;
Brown et al., Language models are few-shot learners. NIPS,2020
但对于每个特定任务找到最优化的提示词很困难。
To模型来源于这篇论文——Sanh et al., 2021. Multitask prompted training enables zero-shot task generalization.
[2]Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
[5]Tianyu Gao, Adam Fisch, and Danqi Chen. 2021b. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
[6]Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021. Ptr: Prompt tuning with rules for text classification.
[17]Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. 2022. Grips: Gradient-free, edit-based instruction search for prompting large language models. arXiv preprint arXiv:2203.07281.
[19]Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-totext transformer. Journal of Machine Learning Research, 21(140):1–67.
[22]Timo Schick and Hinrich Schütze. 2021. Generating datasets with pretrained language models. Computing Research Repository, arXiv:2104.07540.
心理学效应
理解和引导自己与朋友;
心理暗示:使得人不自觉地按照一定的方式去行动,不加批判地接受一定的观念。
瓦伦达效应:
美国一个走钢丝演员在特别想成功的一场演出上失败了。
做法:1、平常心 2、专注事情本身,而非其结果。 3、抗干扰,其他事情与我无关。4、用暗示性动作或者自己习惯的场景让自己处于一种适合做事的条件下,类似于条件概率,让大脑和身体习惯 5、熟练度max,即使干扰也不影响。
4、5都是重复,更大的来说所有做法都是重复形成习惯。
酸葡萄/甜柠檬效应
狐狸想尽办法也吃不到葡萄。“嗯,那个葡萄一定非常酸.””
实在得不到的,可以不要太执着,肯定是坏的,但是不要丢掉上进心;
自卑时,自己拥有的是最好的,注意其中的度。
罗森塔尔效应
随机挑选孩子,对老师说这些学生是可造之才。
权威的延誉会让周围的人对某个人的心理评价变高,通过日常行为体现出来,被期待的人受到这种鼓舞,成绩变得更好。
反思:1.从朋友和老师亲人的正面评价中汲取力量
2.相信朋友会成长得越来越好,实现他的目标。
3.对一个人的喜欢和赞赏,无须直接说话,从众多细节中可以体现出来。细细品味,你会发现身边人的态度。
飞轮效应
万事开头难;惯性的作用,一开始会比较费劲,之后就轻松了,按部就班就可以。
3.前面的努力,都会变成后面的推动力。永远相信付出的努力会在某一天给自己回报。
4.增强回路的过程。因曾强果,果又反过来增强因,循环往复。重视反馈,给自己暗示的反馈,给自己找进步空间。
蘑菇效应
生长在阴暗角落的蘑菇,无人关注,没有阳光,常常自生自灭。只有自己长得高大了,才会被人发现,发挥出作用。
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
提供了一个Tensorflow实现的 新的基准数据集的训练和测试代码 。
这篇论文和之前读过的Few-Shot13:《Learning a Universal Template for Few-shot Dataset Generalization》,
以及《CrossTransformers: spatially-aware few-shot transfer》的代码都是同一批作者的研究,
《Self-Support Few-Shot Semantic Segmentation》,用自支持匹配获得更好的特征原型。Self-Support-Code06
度量学习
(PN、MN、RN、CrossTransformerLearner),
优化学习
1.proto_maml_fc
2.BaselineFinetune
3.proto
最差的:关系网络。
(、maml、almost-no-inner-loop、GenerativeClassifier),
FLUTEFiLM
10个数据集

一些推荐参数
- inner learning rate α=0.1
可继续研究的新问题
训练episode、校验、初始化的最优策略未明;
在多个来源的数据
元学习在网络空间安全方面的使用调查
百度飞桨平台上关于元学习的部分 Code04
https://paddlepedia.readthedocs.io/en/latest/tutorials/meta_learning/了解匹配网络、关系网络、原型等基于度量的小样本学习方法的工作原理。
元学习的五个研究方向:model-based, metric-based, optimization-based, online-learning-based:OML, and stacked ensemble-based models
模型(model-based、)、数据、算法(包括optimization-based、metric-based、stacked ensemble-based models:Meta-learner)
基于度量:HABPN
基于优化
基于模型:MANN、MetaGAN