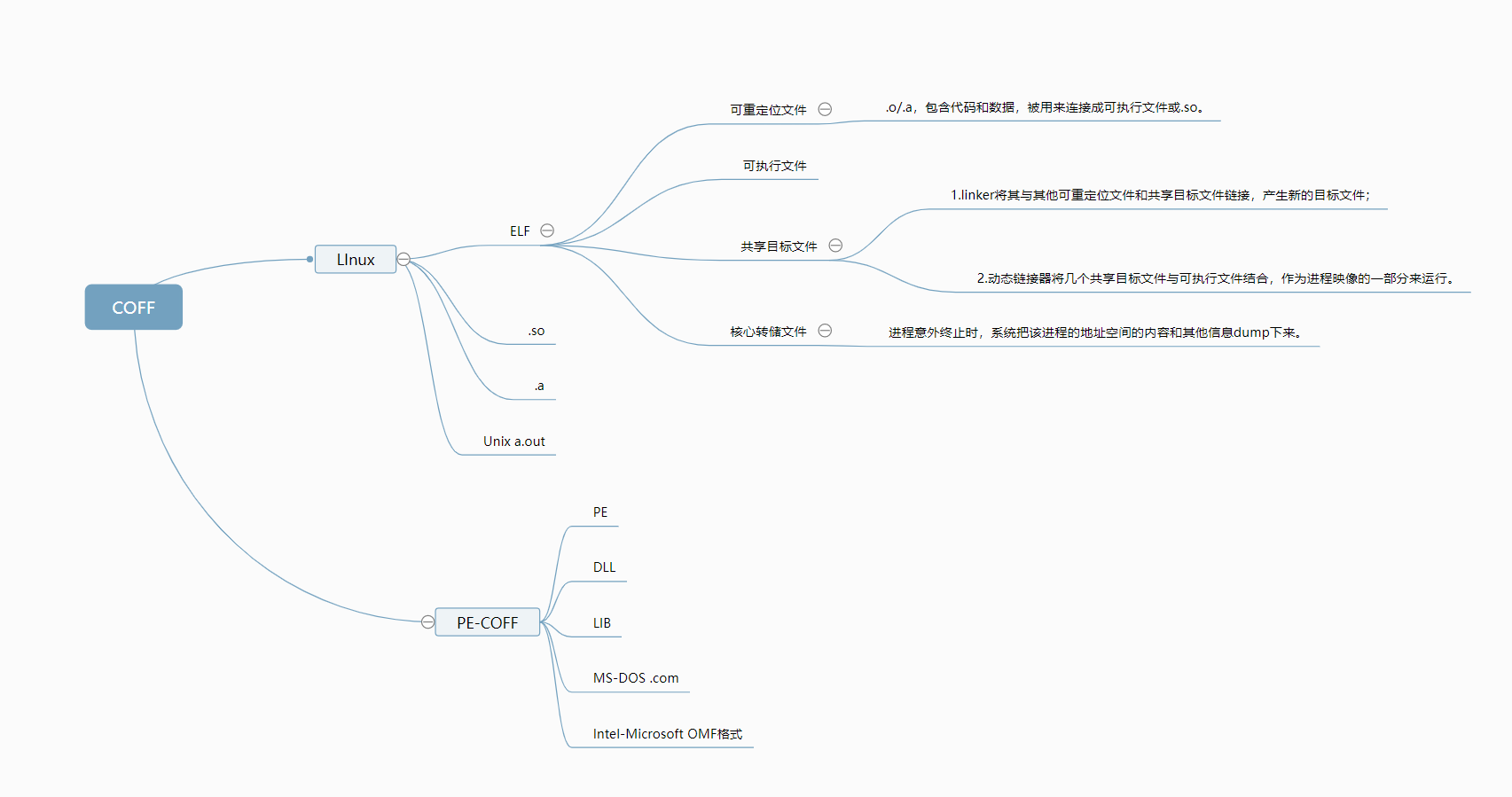
[8]提出了提高特征表示质量的两种新机制。一是通过重新解释user-defined function calls的操作码序列来捕获这些函数调用的语义;二是将文字信息整合到函数调用图FCG的嵌入中,以实现更好的判别能力。在静态检测的背景下,通过采用所提出的两种机制,五个广泛采用的分类器对恶意软件家族分类的准确率平均提高了 2%。。。。(表示)
[5] shah, I.A., Mehmood, A., Khan, A.N. et al. HeuCrip: a malware detection approach for internet of battlefield things. Cluster Comput26, 977–992 (2023). https://doi.org/10.1007/s10586-022-03618-y
[6] Deng H, Guo C, Shen G, et al. MCTVD: A malware classification method based on three-channel visualization and deep learning[J]. Computers & Security, 2023, 126: 103084.
[7] Habibi O, Chemmakha M, Lazaar M. Performance Evaluation of CNN and Pre-trained Models for Malware Classification[J]. Arabian Journal for Science and Engineering, 2023: 1-15.
[8] Wu C Y, Ban T, Cheng S M, et al. IoT malware classification based on reinterpreted function-call graphs[J]. Computers & Security, 2023, 125: 103060.
[9] Malhotra V, Potika K, Stamp M. A Comparison of Graph Neural Networks for Malware Classification[J]. arXiv preprint arXiv:2303.12812, 2023.
[10] Chaganti R, Ravi V, Pham T D. A multi-view feature fusion approach for effective malware classification using Deep Learning[J]. Journal of Information Security and Applications, 2023, 72: 103402.
[11] 利用节表的注入欺骗分类模型。da Silva A A, Pamplona Segundo M. On deceiving malware classification with section injection[J]. Machine Learning and Knowledge Extraction, 2023, 5(1): 144-168.
Ravi V, Alazab M. Attention‐based convolutional neural network deep learning approach for robust malware classification[J]. Computational Intelligence, 2023, 39(1): 145-168.
Chaudhuri A, Nandi A, Pradhan B. A Dynamic Weighted Federated Learning for Android Malware Classification[M]//Soft Computing: Theories and Applications: Proceedings of SoCTA 2022. Singapore: Springer Nature Singapore, 2023: 147-159.
3.伪装c++代码: push eax mov ebp,esp push -1 push 111111 push 111111 mov eax,fs:[0] push eax mov fs:[0],esp pop eax mov fs:[0],eax pop eax pop eax pop eax pop eax mov ebp,eax nop nop jmp 原入口地址
4.伪装Microsoft Visual C++ 6.0代码:
PUSH -1 PUSH 0 PUSH 0 MOV EAX,DWORD PTR FS:[0] PUSH EAX MOV DWORD PTR FS:[0],ESP SUB ESP,1 PUSH EBX PUSH ESI PUSH EDI POP EAX POP EAX nop POP EAX nop ADD ESP,1 POP EAX MOV DWORD PTR FS:[0],EAX POP EAX POP EAX nop POP EAX nop POP EAX MOV EBP,EAX JMP 原入口地址
5.伪装防杀精灵一号防杀代码: push ebp mov ebp,esp push -1 push 666666 push 888888 mov eax,dword ptr fs:[0] nop mov dword ptr fs:[0],esp nop mov dword ptr fs:[0],eax pop eax pop eax pop eax pop eax mov ebp,eax jmp 原入口地址
6.伪装防杀精灵二号防杀代码: push ebp mov ebp,esp push -1 push 0 push 0 mov eax,dword ptr fs:[0] push eax mov dword ptr fs:[0],esp sub esp,68 push ebx push esi push edi pop eax pop eax pop eax add esp,68 pop eax mov dword ptr fs:[0],eax pop eax pop eax pop eax pop eax mov ebp,eax jmp 原入口地址
Hanwei Xu, Yujun Chen, Yulun Du, Nan Shao, Wang Yanggang, Haiyu Li, and Zhilin Yang. 2022. GPS: Genetic Prompt Search for Efficient Few-Shot Learning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8162–8171, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
SC:续写句子(sentence continuation)。采用和论文[22]中一样的根据指令生成数据集方法,采用模板“Write two sentences that mean the same thing. Sentence 1: Manual Prompt, Sentence 2:” 交给预训练模型去续写。采用了GPT2-XL (1.5B)和 T5LM-XXL (11B)作为提示词生成模型。
自然语言推理任务(natural language inference):ANLI R1, ANLI R2, ANLI R3, CB, RTE
共指解析(coreference resolution):WSC, Winogrande
语句补全(sentence completion):COPA, HellaSwag
词义消歧(word sense disambiguation):WiC
方法
参数设置
PT
Adafactor Optimizer,lr=0.05
MT
Adafactor Optimizer,,lr=5e-5=0.00005
BBT
本征维度=500,pop size=20,使用交叉熵损失; 软提示词标记数量为1 or 50时结果最好
ICL
每个task随机从训练集挑2个样本
GRIPS
复用arXiv:2203.07281.里的超参数,将初始提示词换成T0的
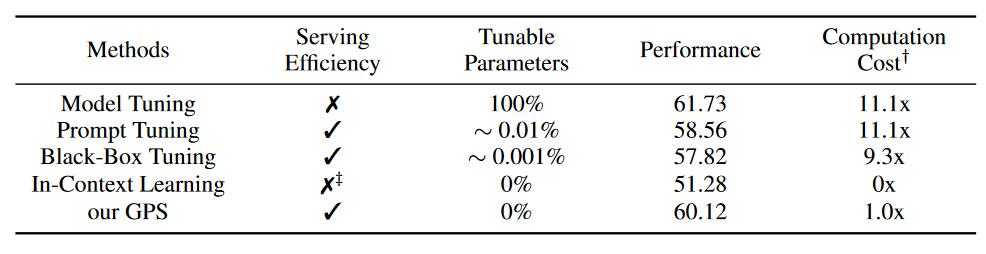
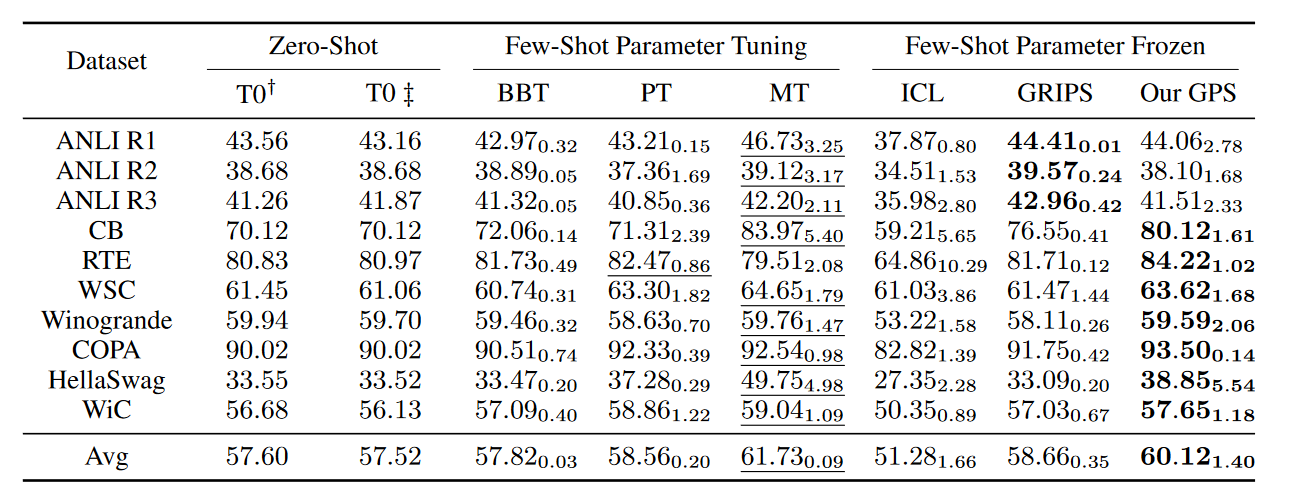
T0、BBT、PT、MT采用相同的人工提示词集,GRIPS和GPS自己搜索提示词。
实验结果是三种不同的数据划分方式的平均结果,脚注是一种方法在一个数据集的三种数据划分下的标准差。
划线部分给出了小样本学习下参数微调得到的最好结果,加粗部分给出了参数冻结方法的最好结果。
Table3 GPS产生的提示词的解释
>
我的未来工作
GPT-3表明,在超大规模预训练语言模型上使用提示词进行小样本学习效果良好;
Brown et al., Language models are few-shot learners. NIPS,2020
但对于每个特定任务找到最优化的提示词很困难。
To模型来源于这篇论文——Sanh et al., 2021. Multitask prompted training enables zero-shot task generalization.
[2]Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
[5]Tianyu Gao, Adam Fisch, and Danqi Chen. 2021b. Making pre-trained language models better few-shot learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3816–3830, Online. Association for Computational Linguistics.
[6]Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021. Ptr: Prompt tuning with rules for text classification.
[17]Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. 2022. Grips: Gradient-free, edit-based instruction search for prompting large language models. arXiv preprint arXiv:2203.07281.
[19]Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-totext transformer. Journal of Machine Learning Research, 21(140):1–67.
[22]Timo Schick and Hinrich Schütze. 2021. Generating datasets with pretrained language models. Computing Research Repository, arXiv:2104.07540.
py310paulc@BlackGame:~$ python Python 3.10.13 (main, Sep 11 2023, 13:44:35) [GCC 11.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> torch.cuda.is_available() True
或者
1 2 3 4
(tf2.9) D:\DataSet\Github\Computed-Tomography-AI>python >>>import tensorflow as tf >>>tf.test.is_gpu_available()