哈密尔顿图
图中存在一条经过所有顶点的回路。(通路~半哈密尔顿图)
根据drebin数据集中的样本特征出现次数占比升序排列如下
1 | u'broadcastreceiverlist_com.google.ads.conversiontracking.installreceiver', |
针对子视图分别生成分类器。同时基于Co-training协同训练算法
基于Zygote注入技术的动态API调用视图的特征提取
编写基于uiautomator框架的用户UI行为模拟程序
基于Xposed框架Hook目标程序的部分安全敏感API
Android系统(Linux)—>init进程 —fork—>zygite进程—>创建Java虚拟机—>
注册JNI调用—>调用Java层的ZygoteInit类的main函数,进入Java世界—>
Java层的ZygoteInit进行如下四步工作:
1.建立一个Socket服务端,监听客户端的连接,用于IPC通信。
2.预加载类和资源(安卓系统启动慢的缘故;加载framework-res.apk中的资源)
3.通过fork的方式,启动system_server进程(system_server是和zygote共存亡的,只要system_server被杀死,zygote也会把自己杀掉,这就导致了系统的重启。)
4.通过调用runSelectLoopMode()方法,进入无限循环,等待客户端的连接请求,并处理请求。(进行必要的native初始化后,主要逻辑都是在Java层完成)
Java native关键字,JNI允许Java代码使用以其他语言编写的代码和代码库。
在Android系统中,zygote(受精卵)是一个native进程,是Android系统上所有应用进程的父进程,我们系统上app的进程都是由这个zygote分裂出来的。zygote则是由Linux系统用户空间的第一个进程——init进程,通过fork的方式创建的。
原生应用是为了在特定设备及其操作系统上使用而构建的,因此它可以使用设备特定的硬件和软件。与开发为跨多个系统通用的网络应用程序相比,原生应用APP程序可以提供优化的性能。
机器学习里除了监督和无监督学习做分类回归,还有强化学习算法用于做决策。
灵感来源于:神经科学和心理学,用外界反馈和暗示加强心理偏向。
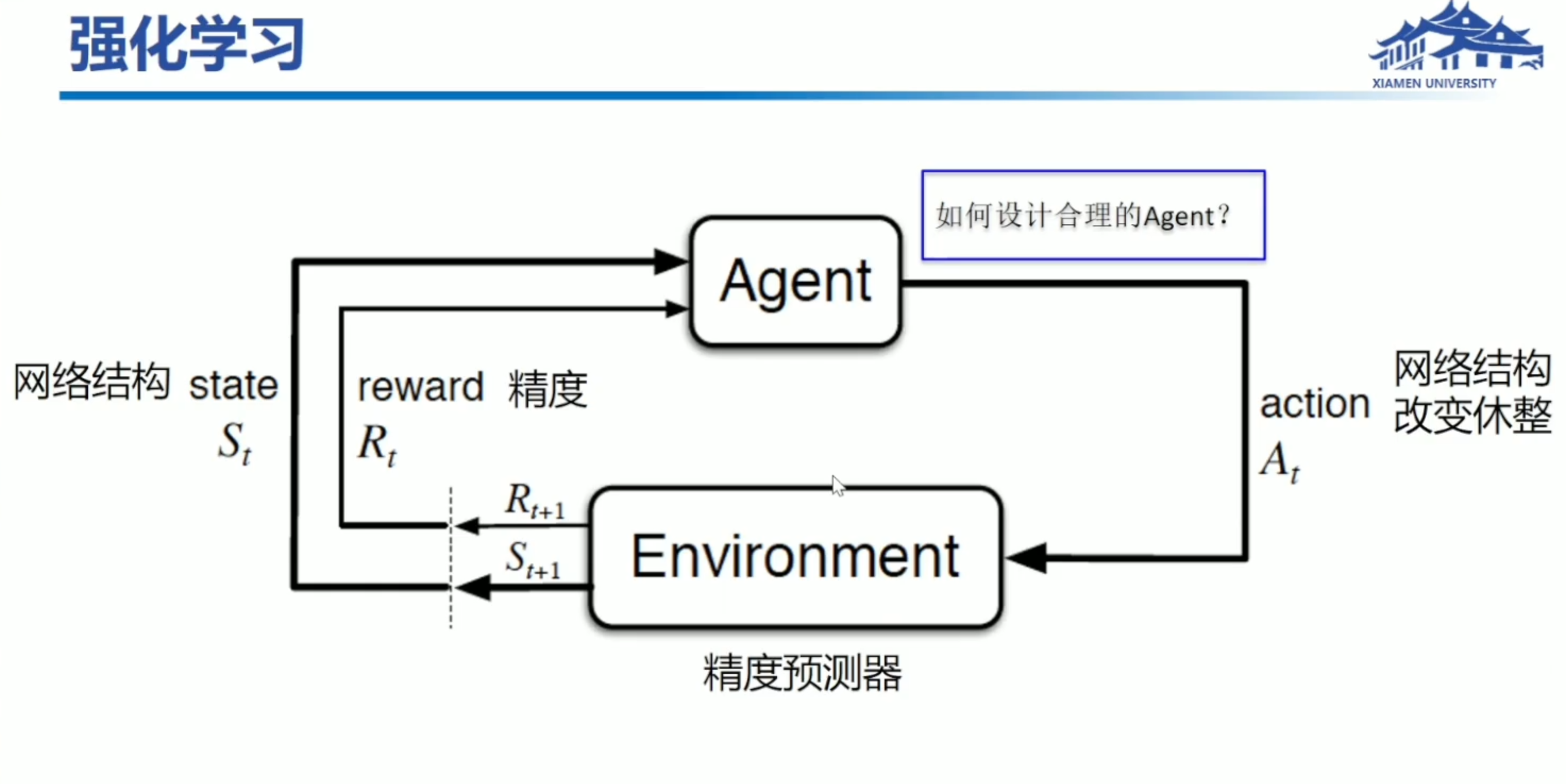
state value,状态值用于评价一个策略好坏。
在正数代表奖励的情况下,0不惩罚,也是一种鼓励。

Reward(s,a),奖励考虑当前状态和行为。
Trajectory(轨迹):状态-动作-奖励 链。
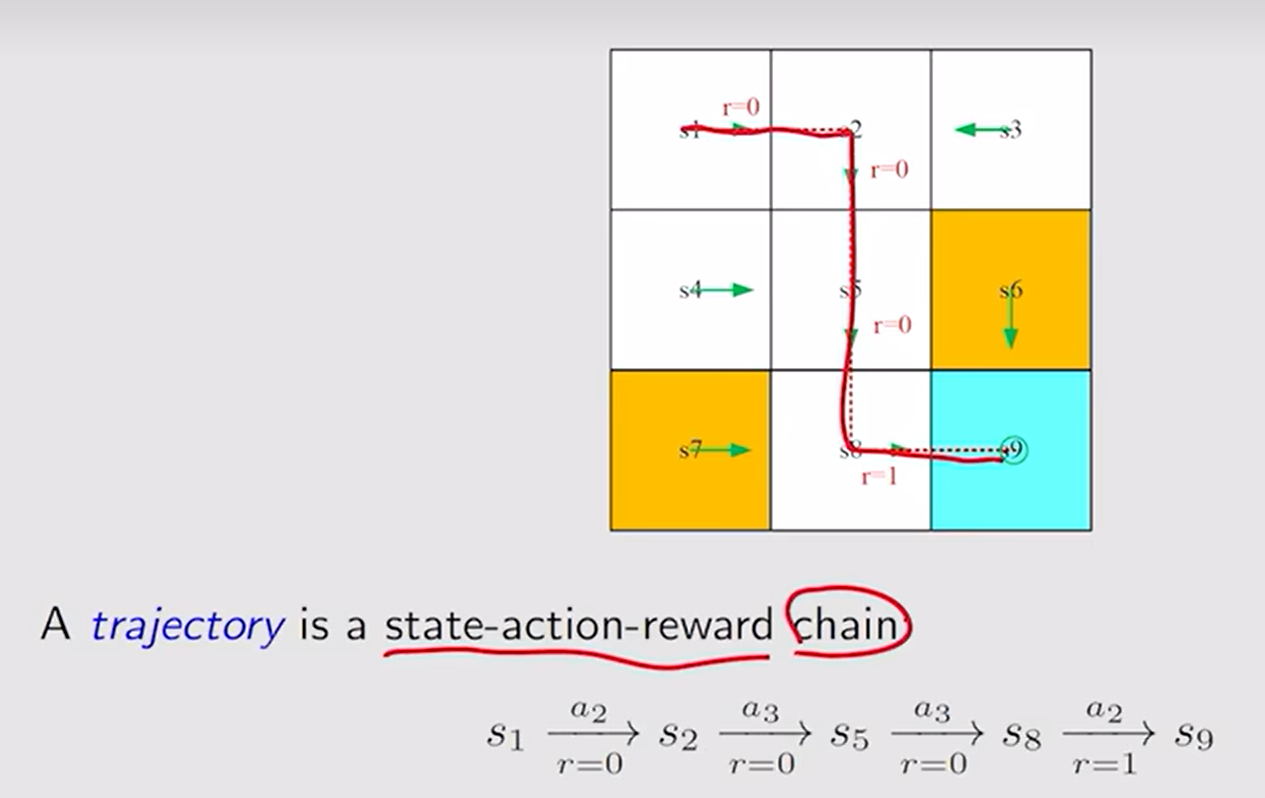
return 是一个轨迹所有的奖励加起来的值。
如return=0+0+0+1=1
而在第9格时所有动作的收益将会一直加一,1+1+1+1+…+1=∞
为避免结果无穷大,引入折扣率,即discount γ∈[0,1],
此时的dicount return=0+γ0+γ^20+γ^3\1+…+γ^n*1=γ^3*1\(1-γ)
γ趋近于0,短视。
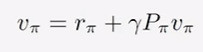
找最优策略,即能够找到的最大状态值对应的策略。
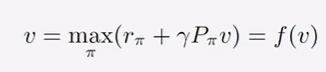
不动点原理=>{最优的策略存在(不一定唯一) ,最优的状态值唯一}
值更新->策略更新->值更新->…,互相促进,最终得到最优策略和最佳状态值。
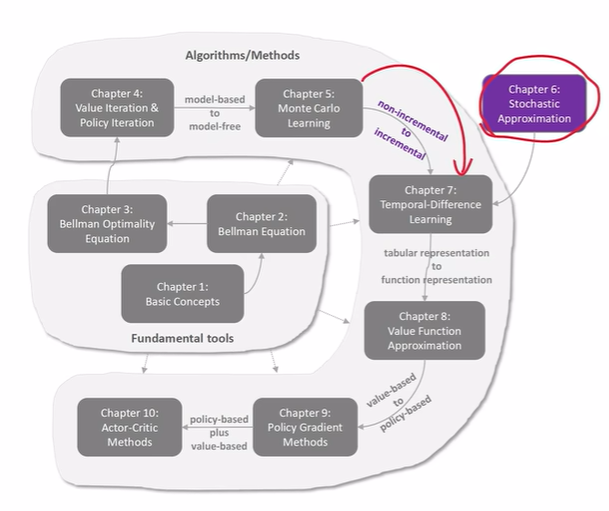
值迭代
策略迭代
截断策略迭代
蒙特卡罗
增量:来一次采样,就可以用它更新估计。
Robbins-Monro算法
SGD
SGD、BGD、MBGD
TD(Temporal Difference)学习状态值
Sarsa:用TD的思想学习action value
Q-learing:直接计算优化的action values;off-policy算法
on-policy :Behavior Policy(生成经验数据)和Target Policy目标策略相同
off-policy:两个策略可以不同
引入函数,让神经网络有机会进入到强化学习。
找一个状态值的近似函数v_hat(S,w)

DQN:两个网络、经验回放
Policy Gradient是一种On-policy的算法

Policy Gradient的一种方法,只是critic部分强调了值的作用。

4)从随机的动作选择策略转到确定性的,就是DPG。
3)通过重要性采样可以把on-policy策略变为off-policy策略。
Security Cookie、SafeSEH、DEP、ASLR、CFG
三A操作:Arrange,Act和Assert。准备数据,运行被测试代码,断言结果。