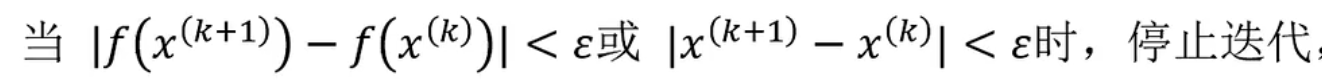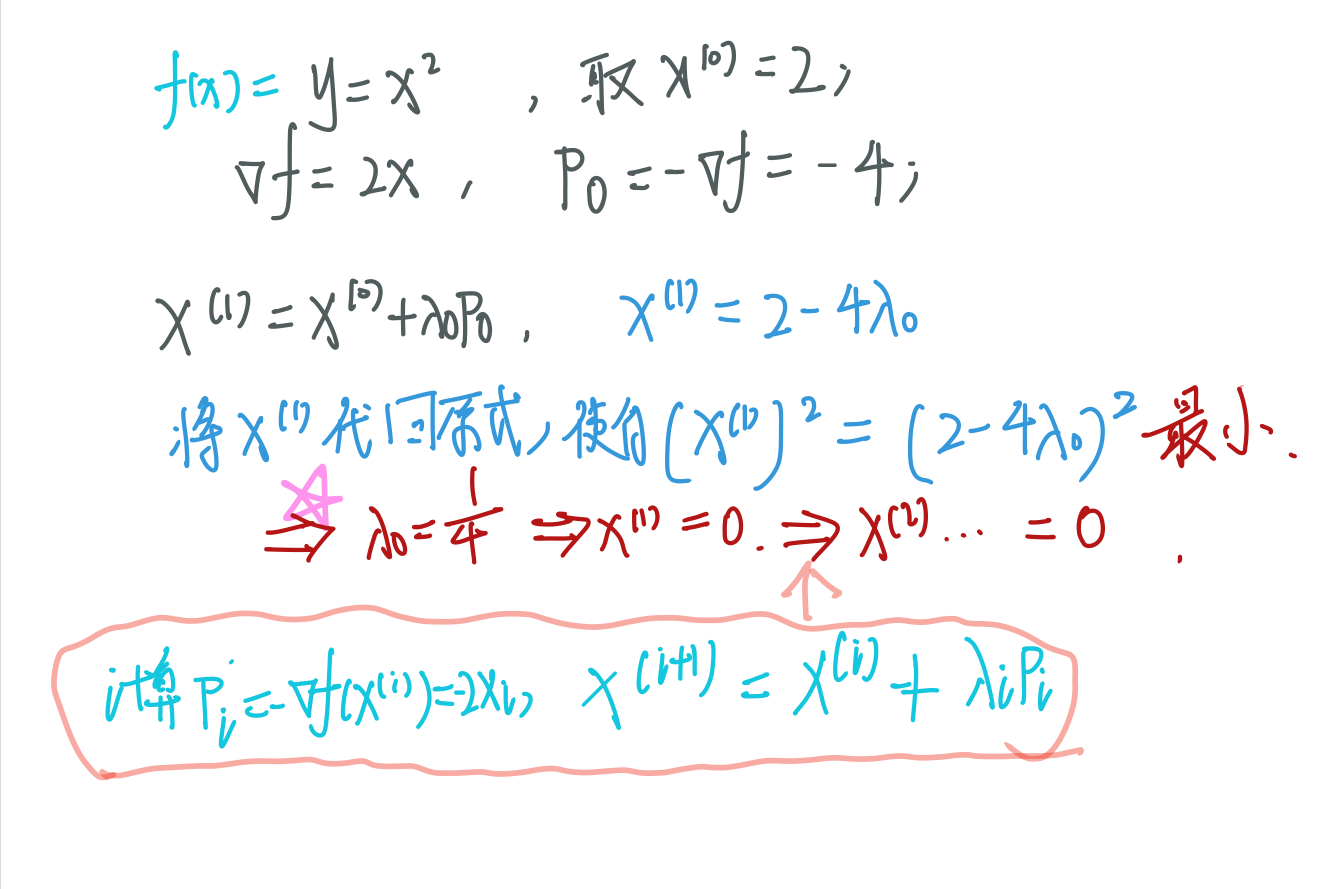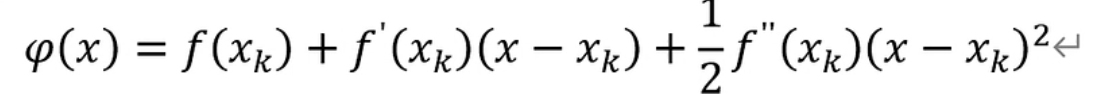subject to s.t. 约束为
最优化问题= 目标函数+约束函数
运筹学里的一种
无约束优化/约束优化
线性/非线性优化 目标函数+约束函数有非线性函数
连续优化(股票投资比例)/离散优化 (如整数规化:路径选择、生产车辆)
单目标优化/多目标优化(考虑多个方面,比如租房)
动态规划
随机规划
鲁棒优化
subject to s.t. 约束为
最优化问题= 目标函数+约束函数
运筹学里的一种
无约束优化/约束优化
线性/非线性优化 目标函数+约束函数有非线性函数
连续优化(股票投资比例)/离散优化 (如整数规化:路径选择、生产车辆)
单目标优化/多目标优化(考虑多个方面,比如租房)
动态规划
随机规划
鲁棒优化
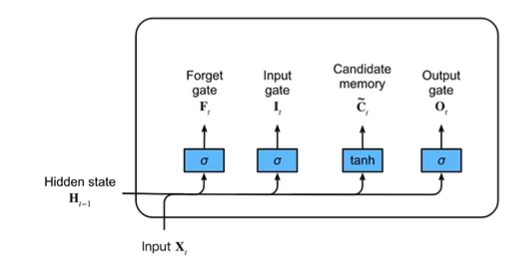
RNN是一个链式结构,每个时间片使用的是相同的参数。常用的是LSTM和GLU。
输入数据要序列化;
具有记忆性、时间维度上权值共享且图灵完备,能够以极高的效率学习序列中的非线性特征。
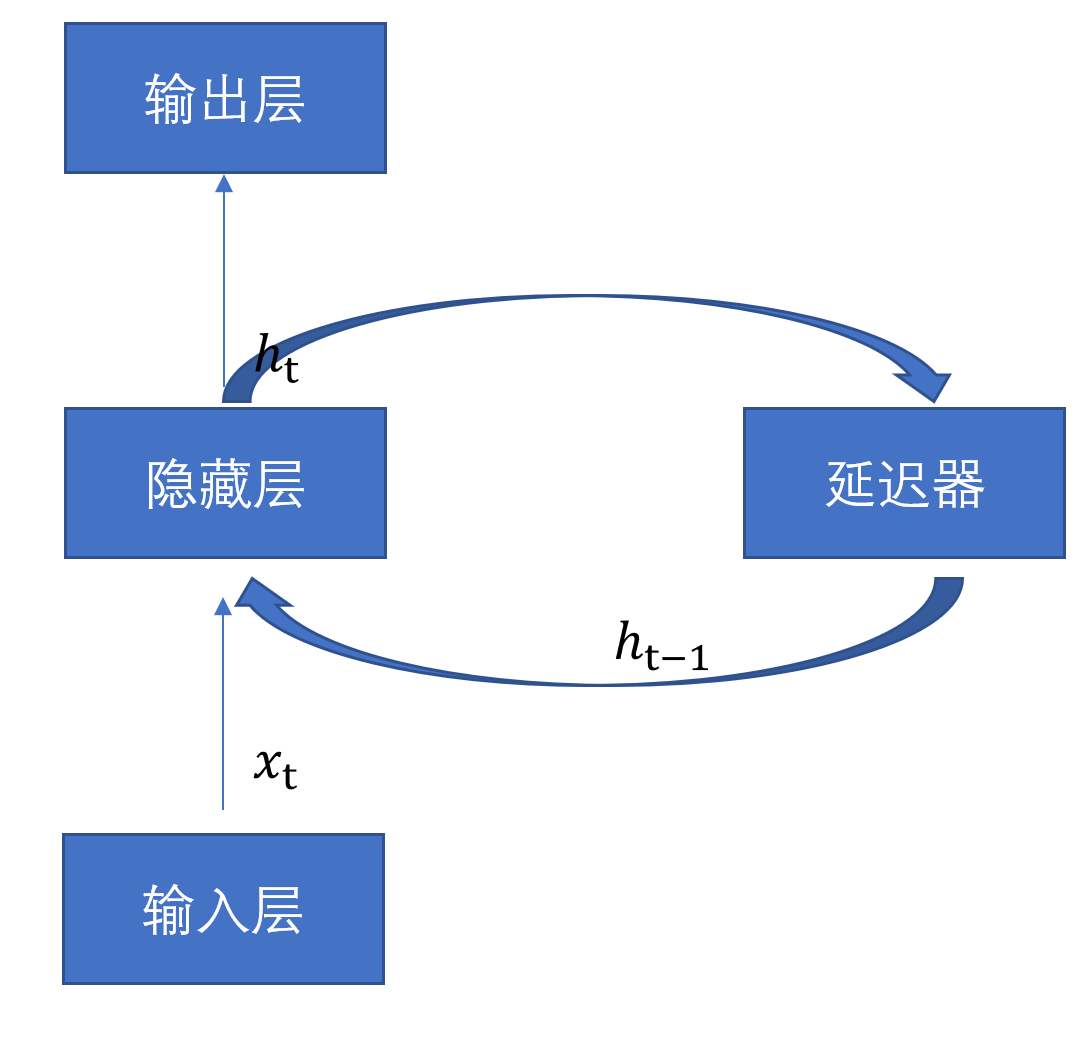
1-1 循环神经网络示例
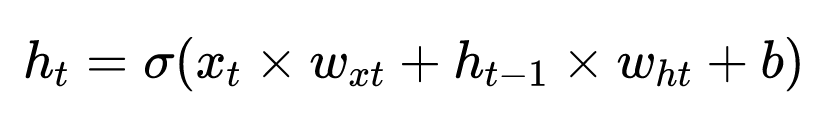
1 | h_{t}=\sigma\left(x_{t} \times w_{x t}+h_{t-1} \times w_{h t}+b\right) |
其中,w_{h t},为状态权重。
长期依赖问题:
隐藏状态h_t只能存储有限的信息,当记忆单元存储内容多时,它会逐渐以往之前所学到的知识(着数据时间片的增加,RNN丧失了连接相隔较远的层之间信息的能力)。
长期依赖的现象也会产生很小的梯度。
梯度消失。梯度爆炸
权值矩阵循环相乘导致。因为RNN中每个时间片使用相同的权值矩阵,相同函数的多次组合会导致极端的非线性行为。
引入门控机制,选择性遗忘一些无用信息,从而控制信息的累积。
Huisman, M., Moerland, T.M., Plaat, A. et al. Are LSTMs good few-shot learners?. Mach Learn 112, 4635–4662 (2023). https://doi.org/10.1007/s10994-023-06394-x
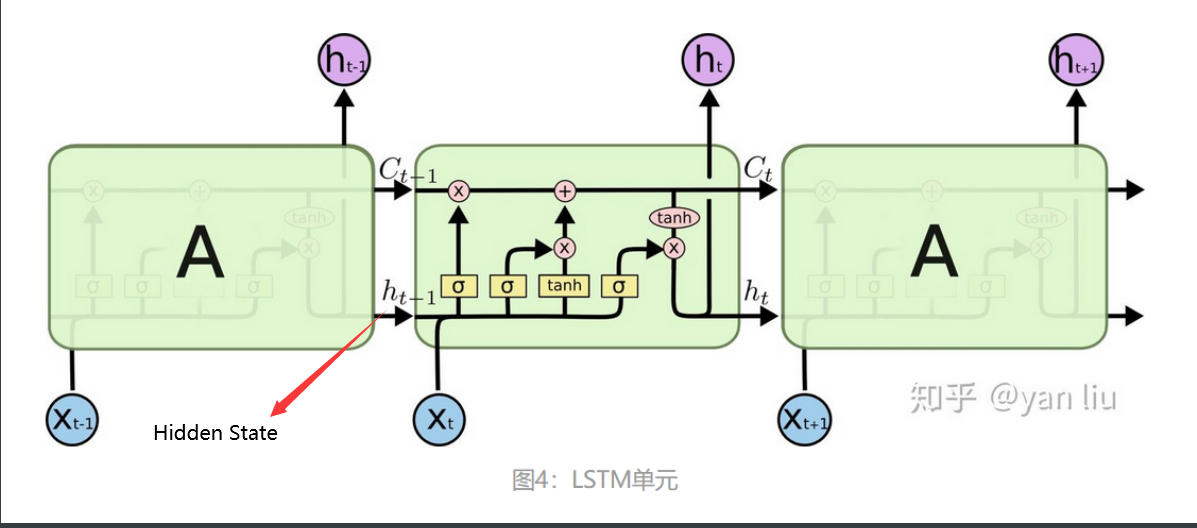
隐状态和记忆单元
1997年由Hochreiter & Schmidhuber提出
Hochreiter, S, and J. Schmidhuber. “Long short-term memory.” Neural Computation 9.8(1997):1735-1780.
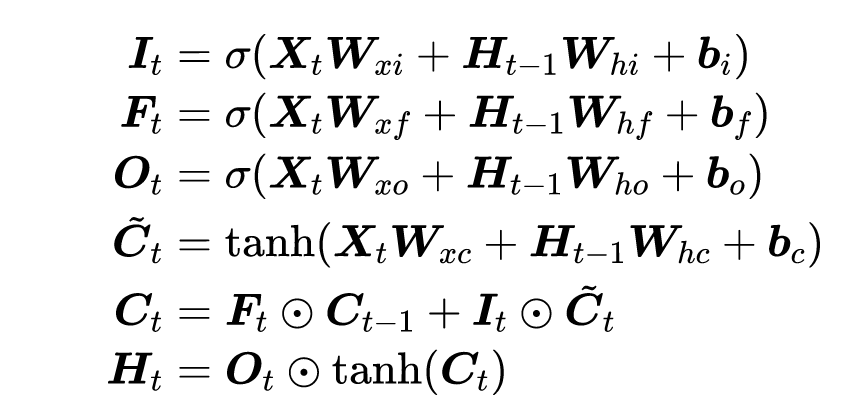
5月26日
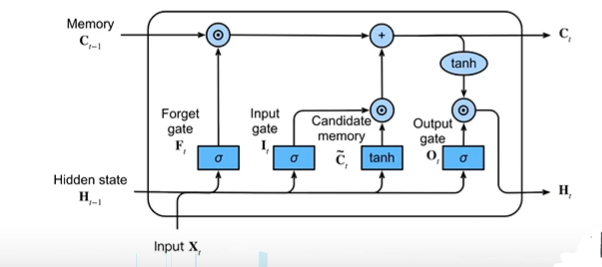
LSTM 可以通过所谓“门”的精细结构向细胞状态添加或移除信息。
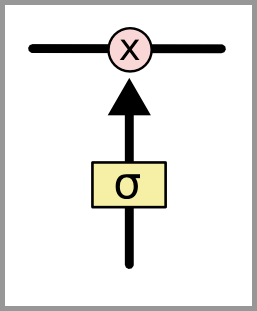
门可以选择性地以让信息通过。它们由 S 形神经网络层和逐点乘法运算组成。
S 形网络的输出值介于 0 和 1 之间,表示有多大比例的信息通过。0 值表示“没有信息通过”,1 值表示“所有信息通过”。
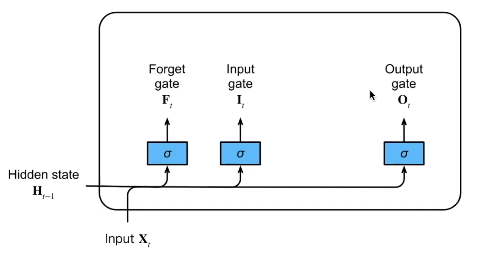
一个 LSTM 有三种这样的门用来保持和控制细胞状态。
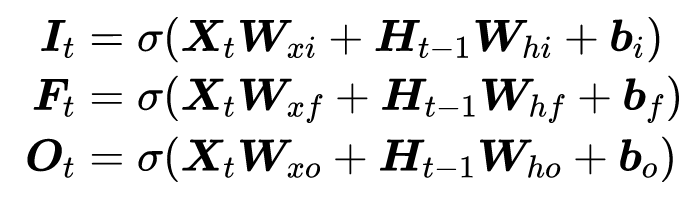
没有用到任何Gate
读法:C_tilda
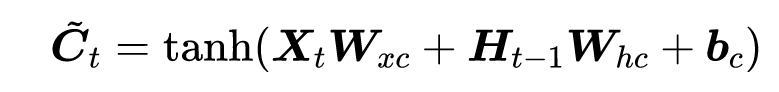
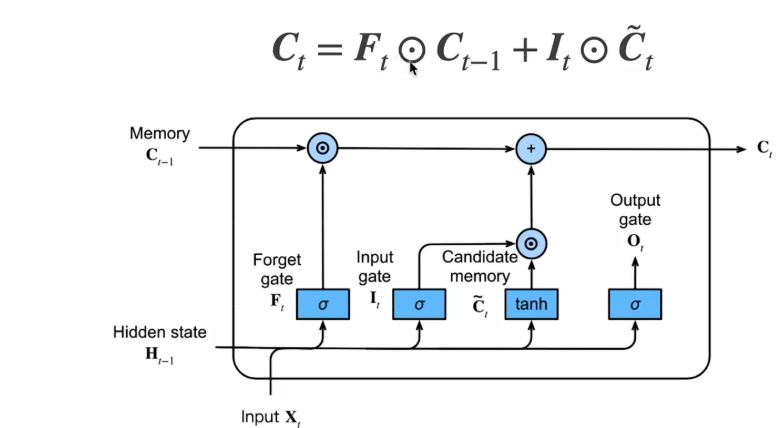
Ct的范围比较大,需要tanh规范到-1到1之间。
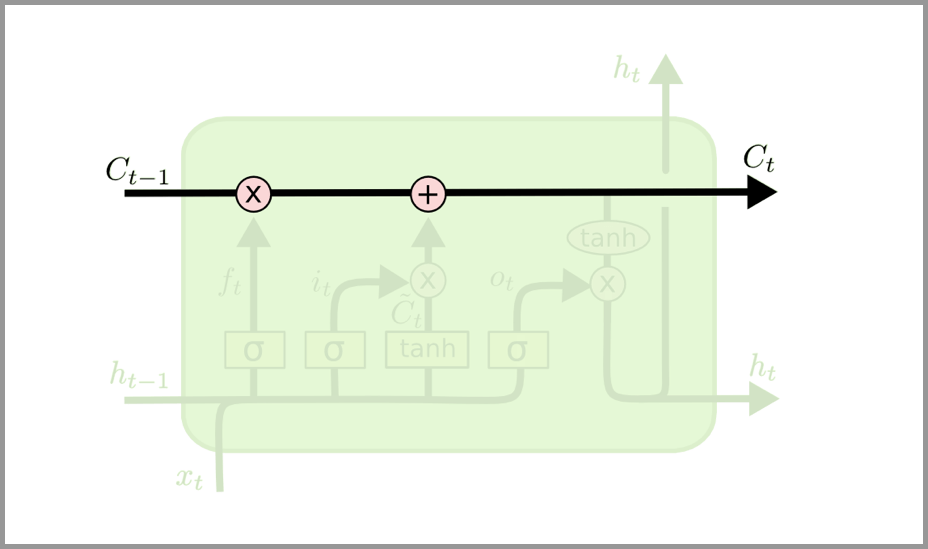
LSTM 的关键是细胞状态,即图中上方的水平线。
细胞状态有点像传送带。它贯穿整个链条,只有一些次要的线性交互作用。信息很容易以不变的方式流过。
让隐藏状态放在+1到-1之间,避免梯度爆炸,降低模型复杂度。
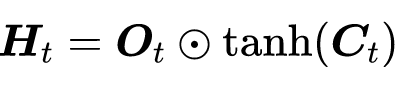
取决于调用的库,对框架的优化,所以最好直接查看实际GPU占用;
这部分内容常用,所以做了一个系统整理;之后会陆续增加点其他内容
查看左边栏的目录进行快速跳转。
防火墙ban了大部分国外服务器的IP,可以轻易检测出没有伪装过的vmess流量,考虑效益,我购买了某机场的会员,价格为30元一个季度,每个月200GB流量。
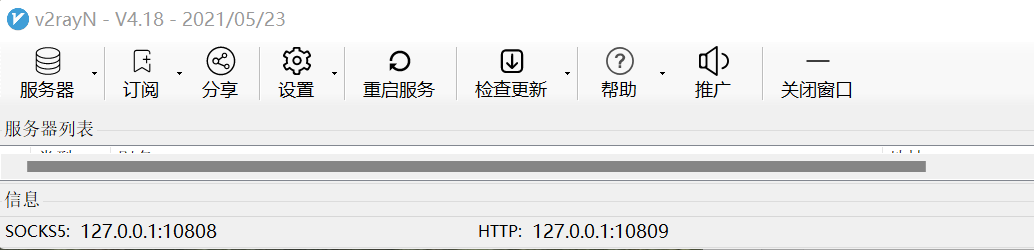
我的真机系统为Win11,使用v2rayN管理连接的服务器和代理端口。
如图所示,我的socks代理端口为10808,http端口为10809。这两种端口,http端口使用的最为频繁。
百度都是直接关闭防火墙,这样不安全,所以写下这一部分内容记录一下步骤。
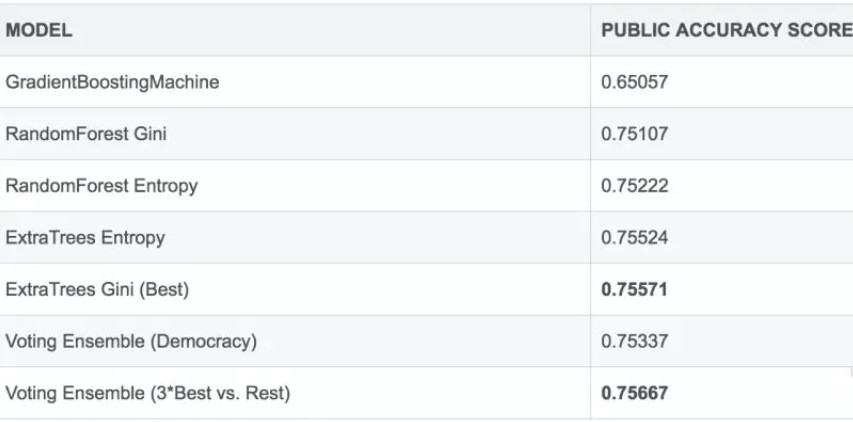
stacking&blending
机器学习比赛大杀器 —— 模型融合,目前只看到排名平均部分。
1.可以集成提交文件(对预测结果的文件进行集成)
2.投票集成(预测结果为类别时) 少数服从多数, 概率意义上相加值大于原来的准确率。
3.集成低相关度的模型(即使其性能较差)也可以提升模型的性能。
原理理解:三个臭皮匠才可以稍微的对诸葛亮的看法做点改进。
通常我们希望模型越好,其权重就越高。比如,我们将表现最好的模型的投票看作3票,其它的4个模型只看作1票。
原因是:当表现较差的模型需要否决表现最好的模型时,唯一的办法是它们集体同意另一种选择。我们期望这样的集成能够对表现最好的模型进行一些修正,带来一些小的提高。
更愿意叫做”bagging Sumissions”。打包提交。
脚本:https://github.com/MLWave/Kaggle-Ensemble-Guide/tree/master/src
平均预测常常会降低过拟合
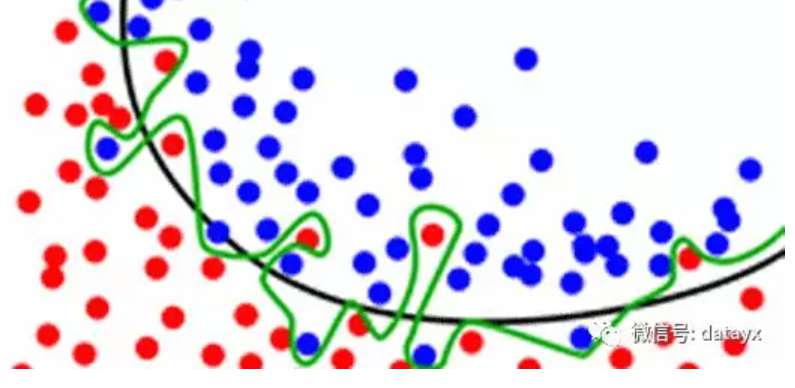
图中黑线比绿线有更好的分割,绿色线已经从数据点中学习了一些噪声。
平均多个不同的绿线, 使其更接近黑线。
我们的目标不仅是去记住这些训练数据(这里有比在随机森林里更加有效的方法来存储数据),而且还要去对我们没有看到的数据进行良好的泛化。
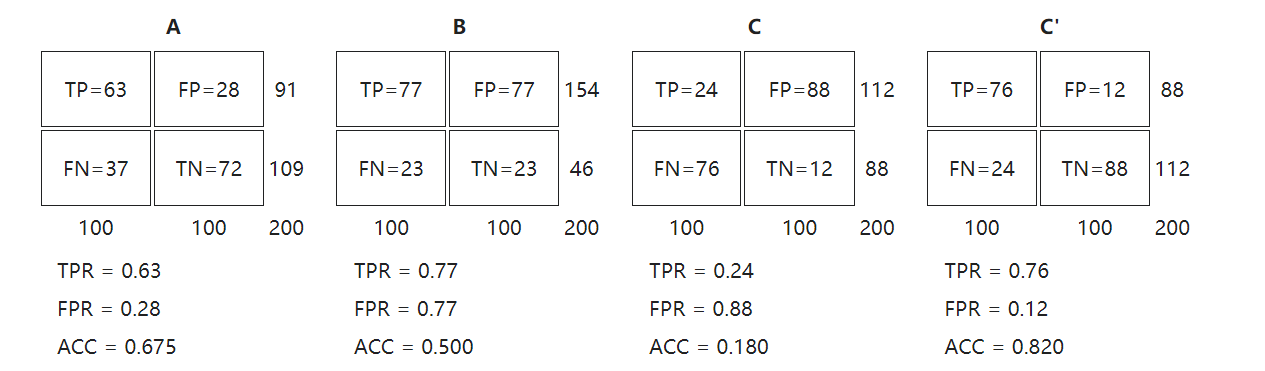
Receiver operating characteristic接收者操作特征
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
又称:错误命中率,假警报率 (false alarm rate)
FPR = FP / N = FP / (FP + TN)
又称:命中率 (hit rate)、敏感度(sensitivity)
TPR = TP / P = TP / (TP+FN)
则(0,1)是完美情况,FP错误的肯定为0,FN错误的否定为0.
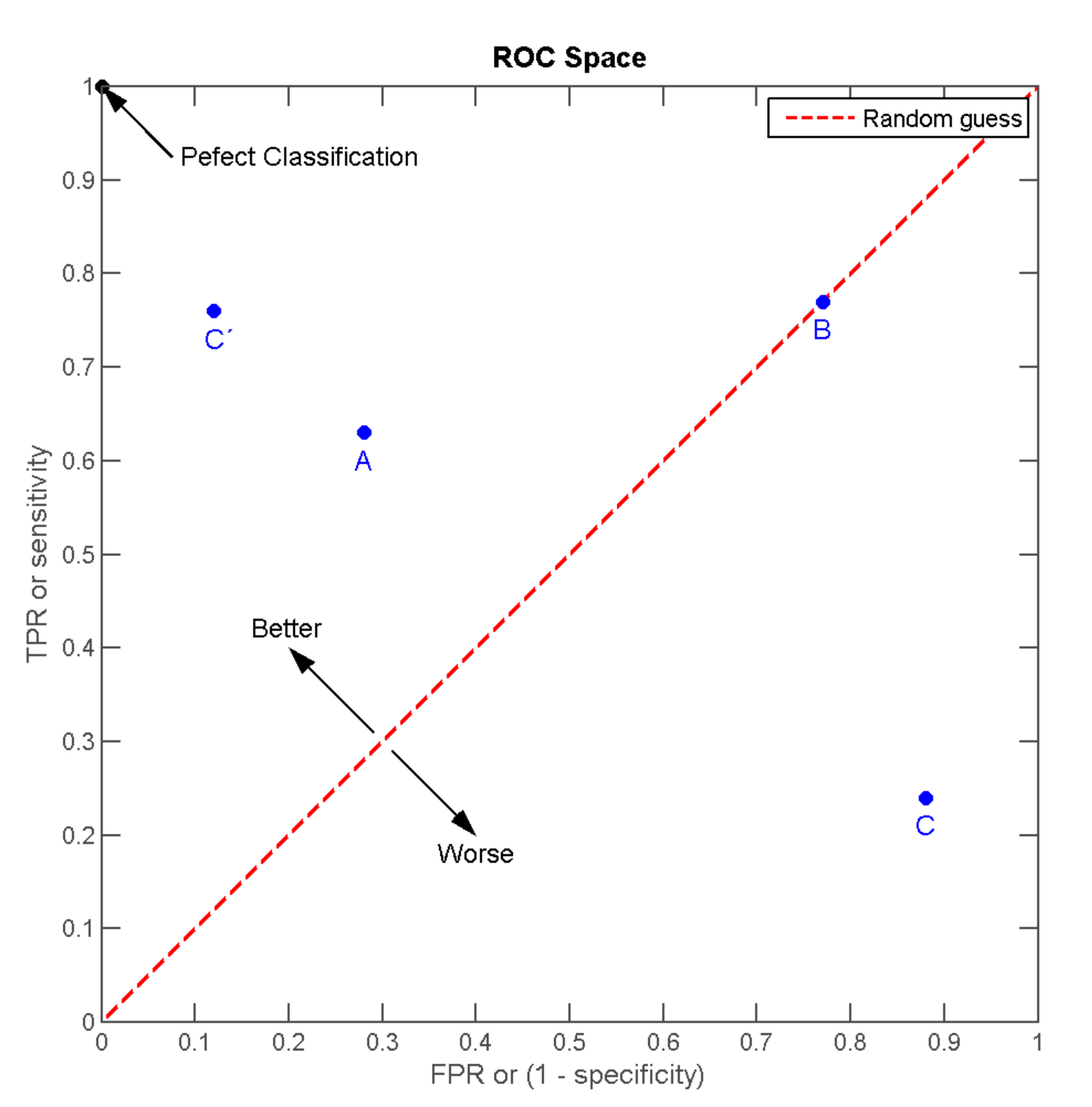
离左上角越近,即x越小、y越大,模型预测准确度越好;
三种模型中,A>B>C但是只要把C当作一个相反结果预测机,则C’>A>B;
调整二分类模型的阈值,得出不同的FPR和TPR,将这些点全部作在一个ROC空间里,就成为特定模型的ROC曲线。
Area Under the Curve of ROC,作为评价模型优劣的指针;取值范围为[0,1]
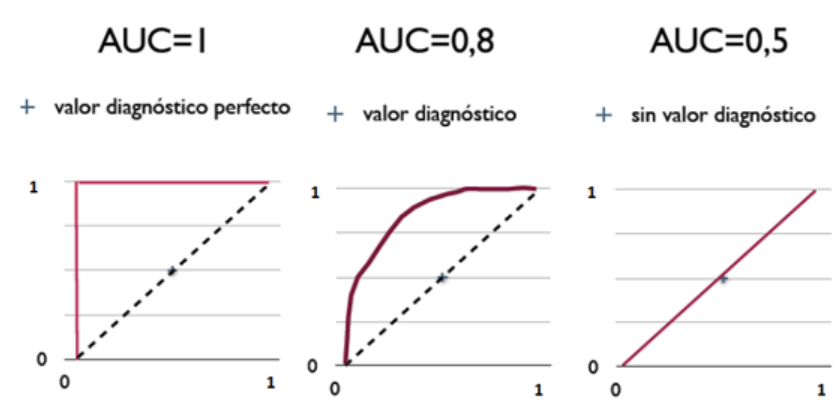
AUC值越大的分类器,正确率越高。
从AUC判断分类器(预测模型)优劣的标准:
全文选摘自:林20的CSDNblog
Linux下权限的粒度有 拥有者 、群组 、其它组 三种。每个文件都可以针对三个粒度,设置不同的rwx(读写执行)权限。
对于user、group、other分别设置三个粒度,则形成了000~777的不同授权数字,分别表示---------和rwxrwxrwx;
实际表示文件时,会采用10位表示法的八进制表示,最高的那一位实际上是拼接上的字母(还有12位二进制的八进制表示,此时要用四个八进制数字)。
持续更新ing
xargs可以解析空格分隔的命令,类似于管道符,但是支持的广泛性上强于管道符。