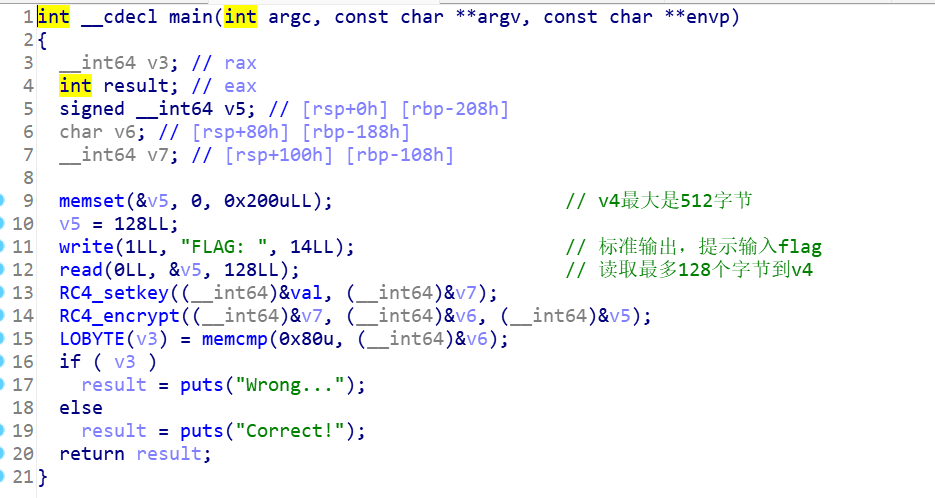
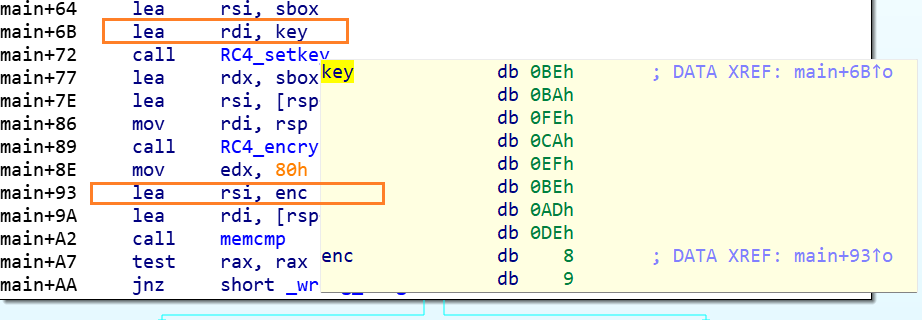
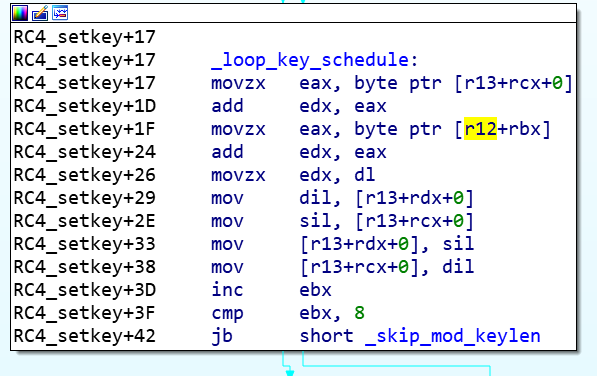
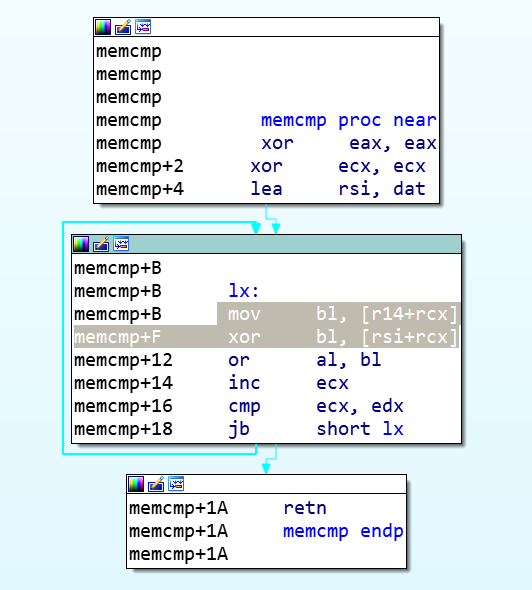
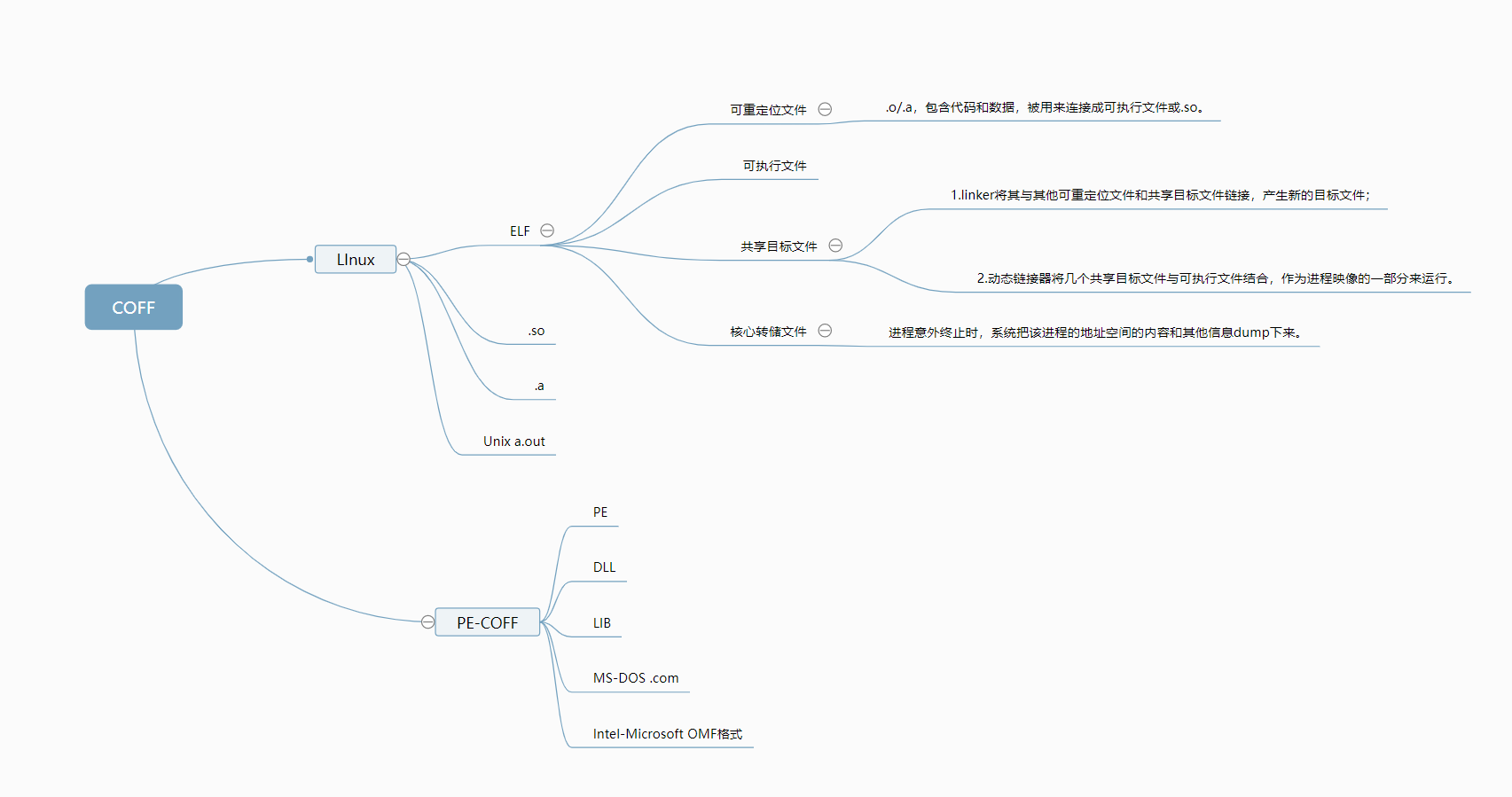
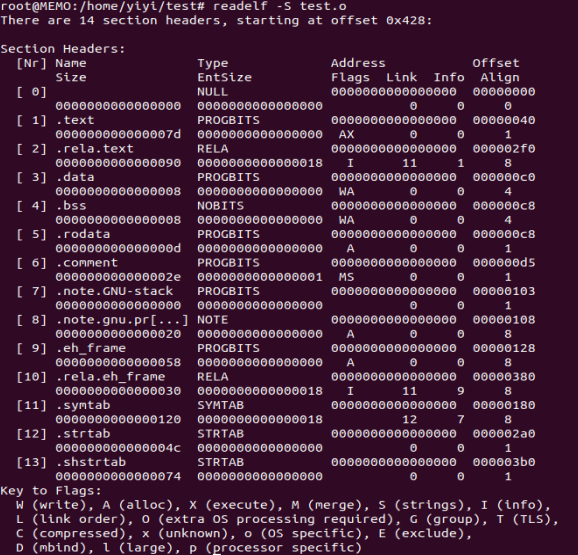
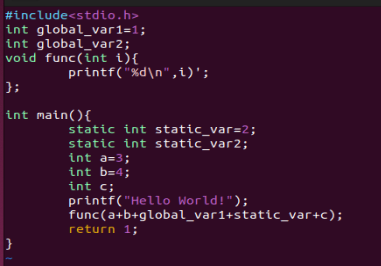
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
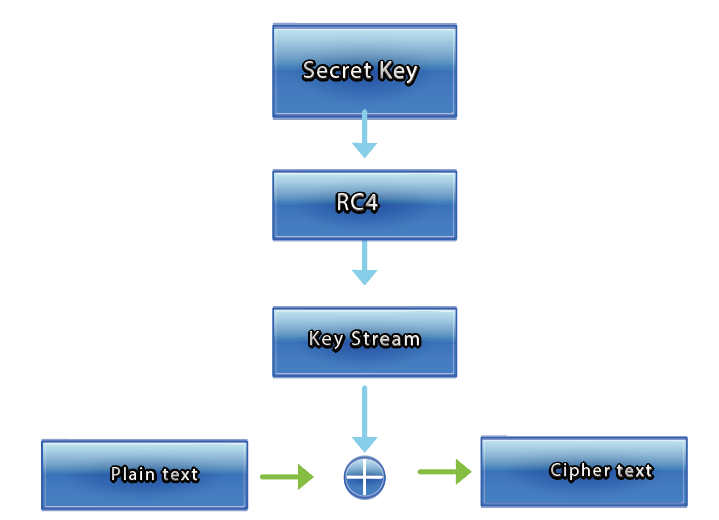
RC4_key= b"\x31\x09\x81\x19\x19\x14\x45\x11"
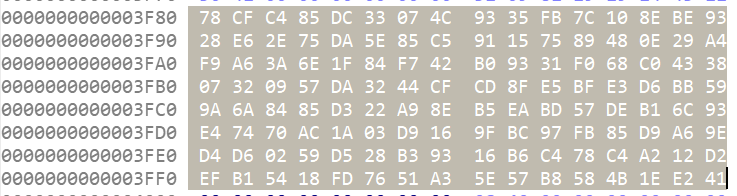
cmp_data =bytes([
0x78, 0xCF, 0xC4, 0x85, 0xDC, 0x33, 0x07, 0x4C, 0x93, 0x35,
0xFB, 0x7C, 0x10, 0x8E, 0xBE, 0x93, 0x28, 0xE6, 0x2E, 0x75,
0xDA, 0x5E, 0x85, 0xC5, 0x91, 0x15, 0x75, 0x89, 0x48, 0x0E,
0x29, 0xA4, 0xF9, 0xA6, 0x3A, 0x6E, 0x1F, 0x84, 0xF7, 0x42,
0xB0, 0x93, 0x31, 0xF0, 0x68, 0xC0, 0x43, 0x38, 0x07, 0x32,
0x09, 0x57, 0xDA, 0x32, 0x44, 0xCF, 0xCD, 0x8F, 0xE5, 0xBF,
0xE3, 0xD6, 0xBB, 0x59, 0x9A, 0x6A, 0x84, 0x85, 0xD3, 0x22,
0xA9, 0x8E, 0xB5, 0xEA, 0xBD, 0x57, 0xDE, 0xB1, 0x6C, 0x93,
0xE4, 0x74, 0x70, 0xAC, 0x1A, 0x03, 0xD9, 0x16, 0x9F, 0xBC,
0x97, 0xFB, 0x85, 0xD9, 0xA6, 0x9E, 0xD4, 0xD6, 0x02, 0x59,
0xD5, 0x28, 0xB3, 0x93, 0x16, 0xB6, 0xC4, 0x78, 0xC4, 0xA2,
0x12, 0xD2, 0xEF, 0xB1, 0x54, 0x18, 0xFD, 0x76, 0x51, 0xA3,
0x5E, 0x57, 0xB8, 0x58, 0x4B, 0x1E, 0xE2, 0x41
])
def RC4_setkey(key, keytable):
keytable_length = 256
for i in range(keytable_length):
keytable[i] = i
j = 0
for i in range(keytable_length):
j = (j + keytable[i] + key[i % len(key)]) % keytable_length
keytable[i], keytable[j] = keytable[j], keytable[i]
return keytable
def filter_printable_chars(flag):
filtered_flag = bytearray()
for byte in flag:
if 0x20 <= byte <= 0x7E:
filtered_flag.append(byte)
return filtered_flag
def gen_keytable(keytable, enc_text):
flag_length = len(enc_text)
v4 = 0
v5 = 0
for v3 in range(flag_length):
v4 = (v4 + 1) % 256
v5 = (keytable[v4] + v5) % 256
keytable[v4], keytable[v5] = keytable[v5], keytable[v4]
return v4,v5
def RC4_decrypt(keytable, enc_text,v4,v5):
flag_length = len(enc_text)
flag = bytearray([0] * flag_length)
for v3 in range(flag_length-1,-1,-1):
flag[v3] = enc_text[v3] ^ keytable[(keytable[v5] + keytable[v4]) % 256]
keytable[v4], keytable[v5] = keytable[v5], keytable[v4]
v5 = (v5-keytable[v4]) % 256
v4 = (v4 - 1) % 256
return flag
RC4_keytable = bytearray([0] * 520)
RC4_setkey(RC4_key, RC4_keytable)
hex_string = ' '.join([f'\\x{byte:02X}' for byte in RC4_keytable])
print("密钥表:\n", hex_string)
v4,v5=gen_keytable(RC4_keytable,cmp_data)
hex_string = ' '.join([f'\\x{byte:02X}' for byte in RC4_keytable])
print(v4,v5)
flag = RC4_decrypt(RC4_keytable, cmp_data,v4,v5)
filtered_flag=filter_printable_chars(flag)
print("Flag:", filtered_flag.decode())
|