xctf的一道Go语言逆向题,涉及AES加密和base64换表加密。
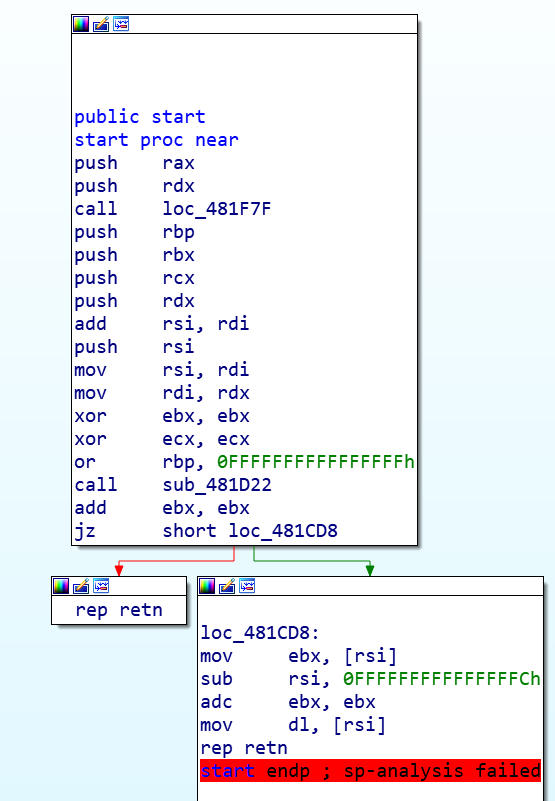
用IDA打开g0Re报告SP-Analysis failed错误。
静态检测
将文件拷贝到kali后,静态检测一番。
1 | $ file g0Re |
报告如下错误:
1 | readelf: Warning: Section 49 has an out of range sh_link value of 2302008908 |
strings找到一些特征字符串1
2
3
4
5
6
7
8
9
10┌──(kali㉿kali)-[~/idawork]
└─$ strings -a -tx g0Re|grep -E '\s{4,30}'
ec OKXX$
13e FN{o
1e6 r mL
284 dRe6eYPgXygMd
295 fSCPpMP/C9DU36D2kliiYS5D9wKG/E_p
2b9 XkJb3WwcGMbUPd63r/bG8gVDS6EsZ5vv
81e18 $Info: This file is packed with the
81e67 $Id:
猜测是UPX加壳,但是UPX标志被抹去了。
UPX! 标志被抹除
unpack时会依次在三个地方检查UPX_MAGIC_LE32(即”UPX!”):
1 | 1、在倒数第36字节偏移处检查,如果特征值不符就会转入throwNotPacked()异常抛出函数,打印not packed by UPX; |

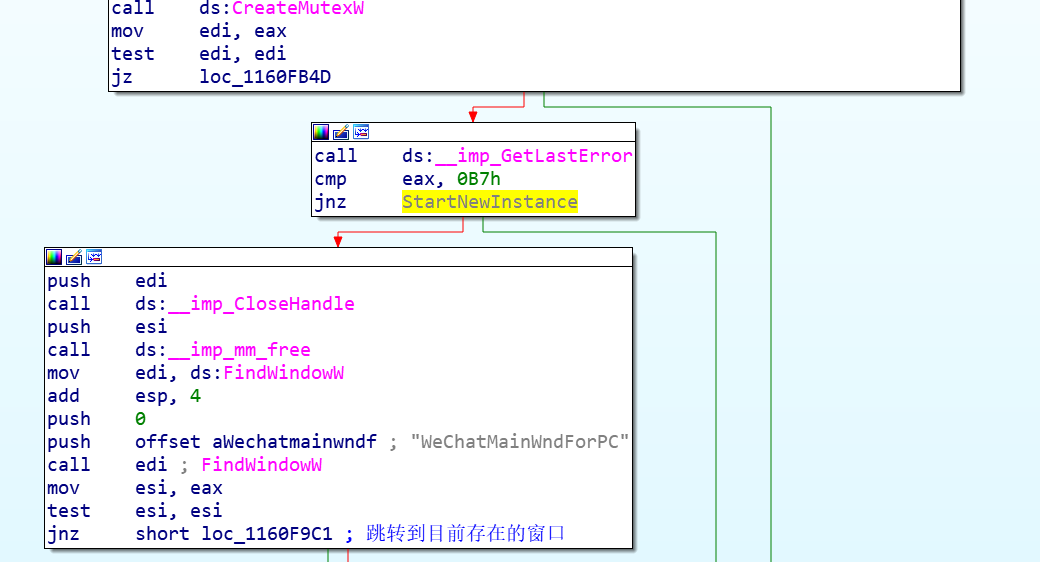
结合上面的规则2,可以很清晰地判断出出题人用0KXX代替了UPX!。
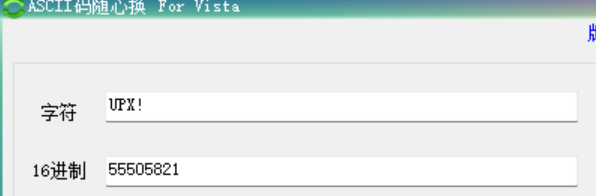
在对应的三个位置处换上UPX!魔数。


upx脱壳。
1 | ┌──(kali㉿kali)-[~/idawork] |
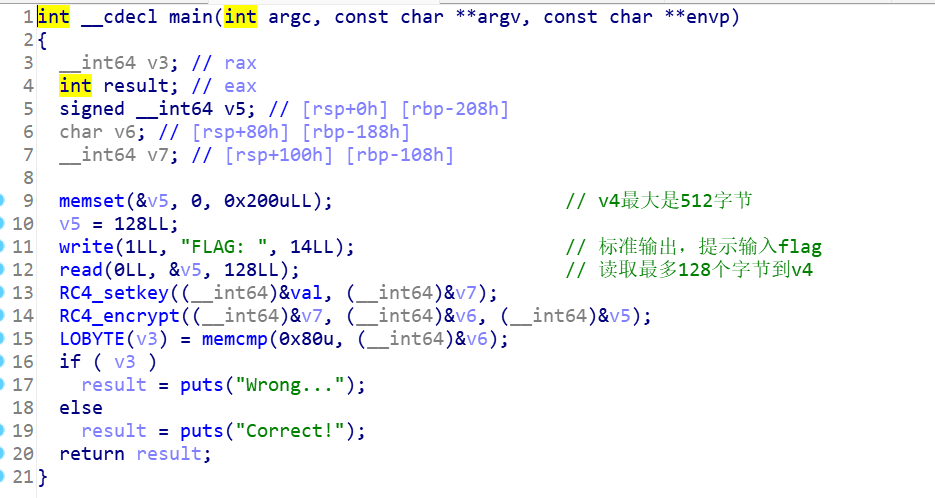
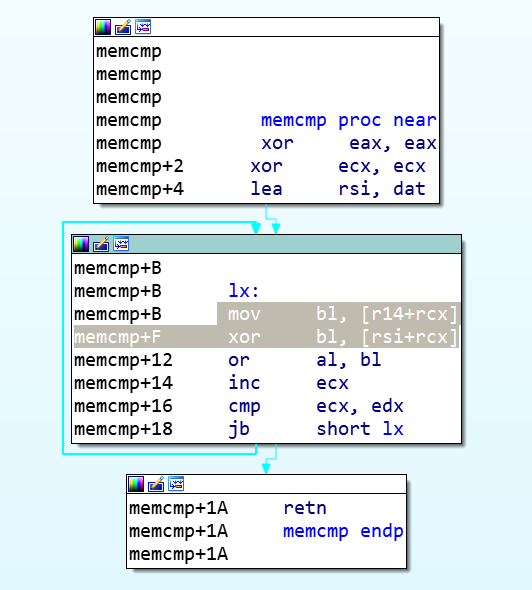
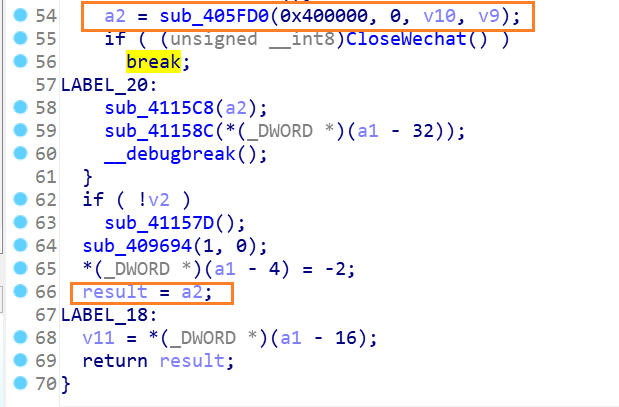
输入flag后的处理流程
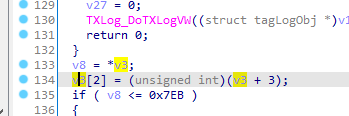
1 | _int64 __usercall sub_48CD80@<rax>(__int64 i%16@<rdi>, __int64 key[i%16]@<rsi>, __int64 a3@<r14>, __int128 a4@<xmm15>) |
1.aes 2.base64 3.简单运算

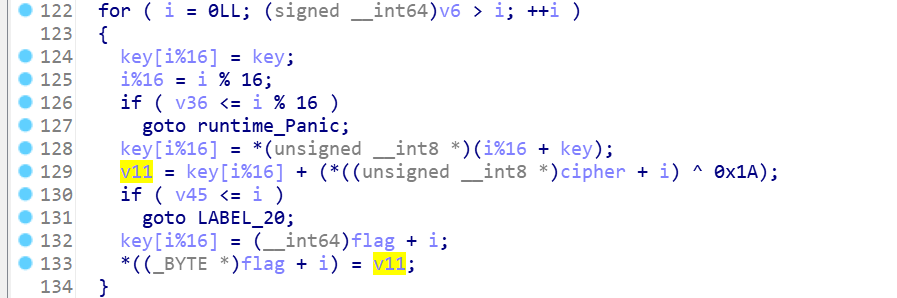
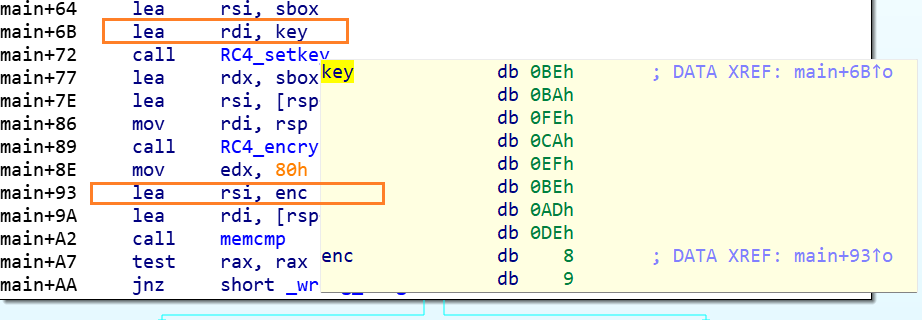
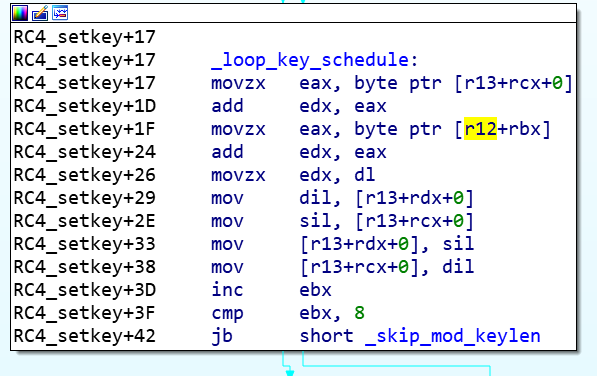
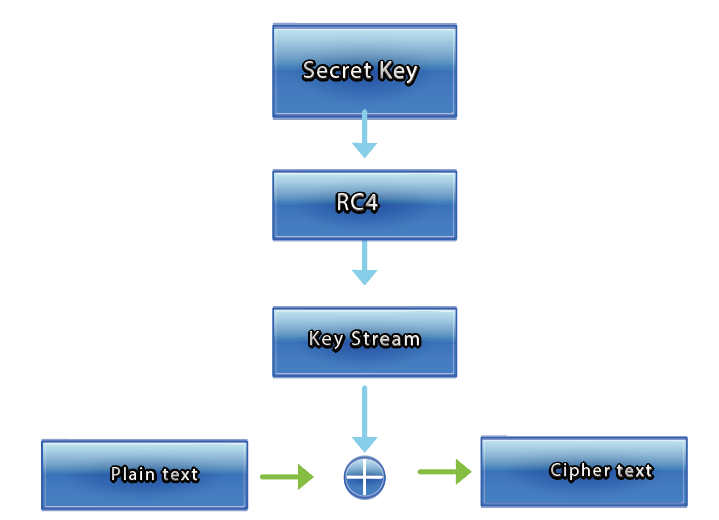
aes加密 密钥获取
1 | 动态调试获取密钥:wvgitbygwbk2b46d |
启动ida服务端。
1 | #端口,密码,详细模式 |
Hex窗口与RSI同步。

base64换表加密
1 | strings -tx g0Re_upx|grep -E '[A-Z]{10,64}' |
解密脚本
1 | #-*-encoding:utf-8 |
反汇编算法
- 1.线性扫描反汇编 关键是确定代码起始位置,之后线性扫描整个代码段,并逐条反汇编每条指令。不会识别分支来解释控制流。
- 优点:覆盖程序的所有代码段;
- 缺点:假设代码段中全是代码,没法处理代码段中混入的数据。
- 2.递归下降反汇编。根据指令间的引用关系决定是否反汇编,在一个代码块内部,还是使用线性扫描算法。
- 优点:大部分情况下可以区分代码和数据。
- 缺点:无法处理间接代码路径。
IDA pro是递归下降反汇编器。
1 | //add、xor、mov、栈操作push |
反汇编出问题的情形
1.对于无条件分支指令,例如jmp eax这样的运行时才能确定跳转地址的指令,需要人工赋值。
2.call指令,在函数内部篡改了函数返回地址。
1 | foo proc near |
3.ret没有提供返回地址。
IDA遇到的函数返回语句,检测到其栈指针值不为0。
反汇编的困难
1.编译,和自然语言的翻译一样是一个多对多操作。除了C编译器,还有Go、Python、Delphi编译器、WinAPI库,反编译器非常依赖语言和库。
2.编译过程中会丢失命名和类型信息。反汇编后最多知道变量的位数,类型信息需要通过变量的用途确定。
一些静态工具用法
Linux:ldd; nm展示符号,C++filter、展示重定义。
OSX:otool; 处理MACH-O。
Windows:VS里的dumpbin /dependents ;objdump
ldd显示依赖库
1 | ┌──(kali㉿kali)-[~/idawork] |
dumpbin /dependents
1 | Dump of file baby.exe |
strings
-t 显示字符的文件偏移
-a 使得strings扫描整个文件,而非只有文件中可加载的、经初始化的部分
-e 搜素其他字符编码,如Unicode
几乎不会用到的工具:x86流式反汇编器,ndisasm和diStorm。