Attack Robustness and Centrality of Complex Networks
Iyer, Swami & Killingback, Timothy & Sundaram, Bala & Wang, Zhen. (2013). Attack Robustness and Centrality of Complex Networks. PloS one. 8. e59613. 10.1371/journal.pone.0059613.
组件失败时系统的稳定性——依赖于底层网络的稳定性——顶点移除时网络结构的改变
- betweenness centrality.
- 基于度分布、聚集系数、组合系数去衡量复杂网络的鲁棒性
研究基于度、中间度、接近度和特征向量中心性的去除方案对各种模型网络的影响,包括幂律和指数分布、不同聚类系数和不同分类程度的模型网络
网络渗流和稳定性
渗透:取一个网络并去除其顶点的某些部分(以及连接到顶点的边)的过程。
对于疫苗接种或者节点失效来说,虽然它物理上还存在,但从功能视图上看一些节点被移除了。
若渗流后的最大组件(相对于原始网络规模)在规模上变得太小,系统不可正常工作。
系统稳定性衡量函数为移除节点的函数:
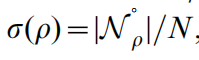
中心性参数(centrality)度数,可以用来衡量节点的重要性程度——。
R-index[13] Mitigation of malicious attacks on networks. Proceedings of the National Academy of Sciences 108: 3838–3841.)
A CLOSER LOOK AT FEW-SHOT CLASSIFICATION
二进制代码相似性研究综述
A Survey of Binary Code Similarity(https://doi.org/10.1145/3446371)
Irfan Ul Haq and Juan Caballero. 2021. A Survey of Binary Code Similarity. ACM Comput. Surv. 54, 3, Article 51 (April 2021), 38 pages.
补丁,漏洞,恶意代码检测,这些技术其实是相通的。
70种恶意代码相似性比较方法:应用领域,方法特点,实施办法,评估基准。
MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network
下载链接 MANNWARE:用记忆增强网络的小样本恶意软件分类方法,2020,小样本学习做恶意代码分类开山作
Tran, Kien & Sato, Hiroshi & Kubo, Masao. (2020). MANNWARE: A Malware Classification Approach with a Few Samples Using a Memory Augmented Neural Network. Information. 11. 51. 10.3390/info11010051.
方法
修改了内存存取能力memory access capabilities的神经图灵机NTM +NLP(word2vec, n-gram)
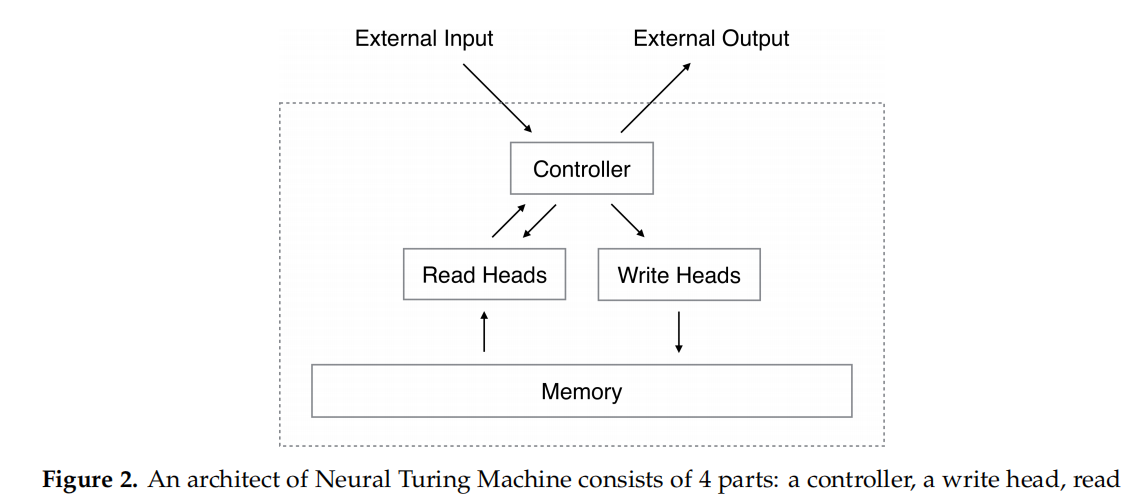
A Few-Shot Meta-Learning based Siamese Neural Network using Entropy Features for Ransomware Classification
下载链接,一种使用熵特征进行勒索软件分类的基于小样本元学习的孪生网络,2022年
Jinting Zhu, Julian Jang-Jaccard, Amardeep Singh, Ian Welch, Harith AI-Sahaf, Seyit Camtepe,
A few-shot meta-learning based siamese neural network using entropy features for ransomware classification,Computers & Security,Volume 117,2022,102691,ISSN 0167-4048,
相关论文Task-Aware Meta Learning-based Siamese Neural Network for Classifying Control Flow Obfuscated Malware
ConvProtoNet: Deep Prototype Induction towards Better Class Representation for Few-Shot Malware Classification
下载链接,卷积原型网络:针对小样本恶意软件分类的更好的类表示的深度原型归纳,2020年
Zhijie, Tang & Wang, Peng & Wang, Junfeng. (2020). ConvProtoNet: Deep Prototype Induction towards Better Class Representation for Few-Shot Malware Classification. Applied Sciences. 10. 2847. 10.3390/app10082847.
方法
模型架构
ConvProtoNet:基于度量(metric-based)的模型,使用了非参数的方法,在嵌入层做了深层的原型归纳,使得表达效果好,分布能匹配,避免了梯度消失,在分析时忽略无用特征。
Task-Aware Meta Learning-based Siamese Neural Network for Classifying Control Flow Obfuscated Malware
下载链接,用于分类混淆恶意软件的基于任务感知的元学习孪生网络,2021
Zhu, Jinting & Jang-Jaccard, Julian & Singh, Amardeep & Watters, Paul & Camtepe, Seyit. (2021). Task-Aware Meta Learning-based Siamese Neural Network for Classifying Obfuscated Malware.
相关论文A Few-Shot Meta-Learning based Siamese Neural Network using Entropy Features for Ransomware Classification
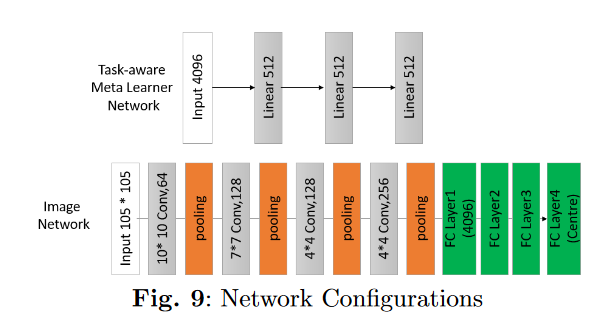
本文的 特征嵌入层 适合 三种类型的控制流混淆的 恶意软件分类
创新点
1、引入熵特征,处理控制流混淆。
2、用两个损失函数分别刻画类间方差和类内方差。为衡量嵌入损失,
- 对于类间方差,在binary loss基础上加入二次嵌入损失
- 对于类内方差,中心损失与对比损失,使得样本对能聚类使得边界更明显。
输入:熵特征,(样本对,样本对标签)
输出:类内距离
图5 模型结构

孪生网络:
含两个相同的子网络,所以叫孪生,输入(样本对,样本对标签),训练获得一个相似度函数以在测试时判断两张图片是否相同,使用监督的交叉熵损失。
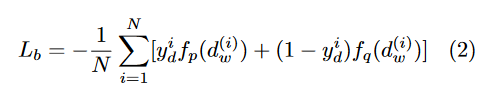
每个子网络的CNN结构,用于找到一个嵌入层进行降维表示。
这个嵌入层,训练阶段用于优化损失;测试阶段,用于生成相似性分数。
模型架构的优势:处理类别不平衡问题,分类新类别时无须再训练网络。
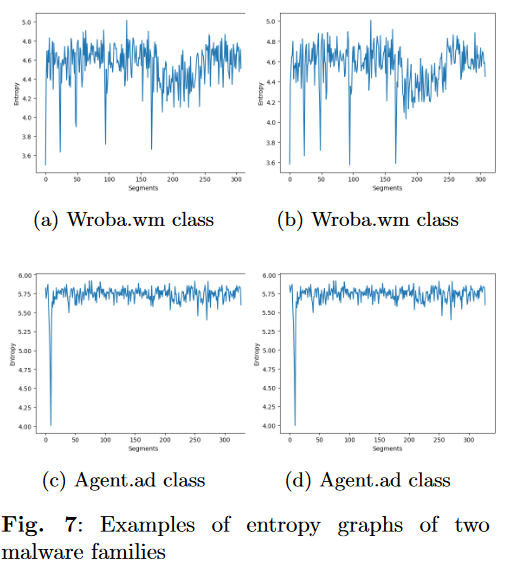
熵特征:
使用香农公式计算字节的出现频率:
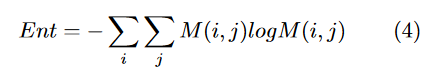

- 将二进制文件分段segment。
- 对于每个段,计算每个字节值(00h-ffh)的频率,计算该段的熵yi。
- 将熵值表示为stream,最后重塑为大小为(254,254,1)的熵图。通过VGG-16,转化为4096维的特征。
实验:
模型,4000万参数规模。
嵌入空间的表示;N-way匹配准确率,AUC (Area Under The Curve) ROC (Receiver Operating Characteristics) 曲线; (5,10,15) way (1,5) shot;
Andro-dumpy datasets
数据集
13个家族的906个二进制恶意软件。
wook Jang J, Kang H, Woo J, et al (2016) Andro-dumpsys: Anti-malware system based on the similarity of malware creator and malware centric information. Computers Security 58:125 – 138. https://doi.org/http: //dx.doi.org/10.1016/j.cose.2015.12.005, URL http://www.sciencedirect.com/science/ article/pii/S016740481600002X
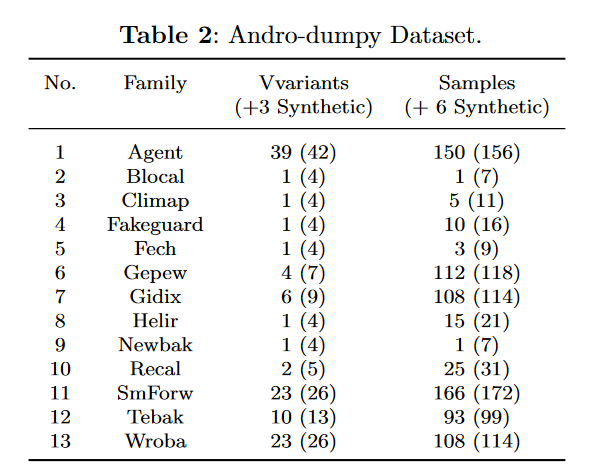
混淆变种的合成。每个家族的变种数量,()里是加上作者的混淆方法后的样本种类数和数量。
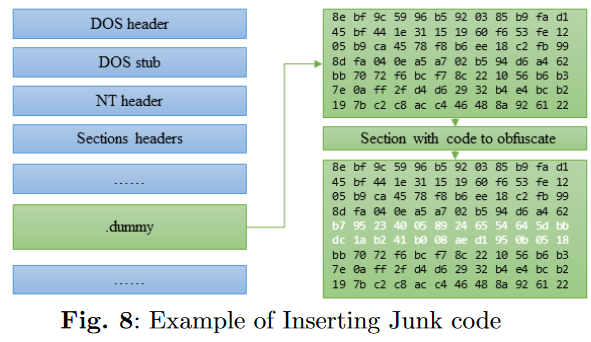
程序转图片
1.字节—>uint8—->2D vector——>固定宽度的变长灰度图——>双线性插值(bilinear interpolation method),生成固定尺寸的图片(105,105)。
插值部分可参考:Malvar HS, He Lw, Cutler R (2004) Highquality linear interpolation for demosaicing of bayer-patterned color images. In: 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, IEEE, pp iii–485
图片增强到每个家族至少30个
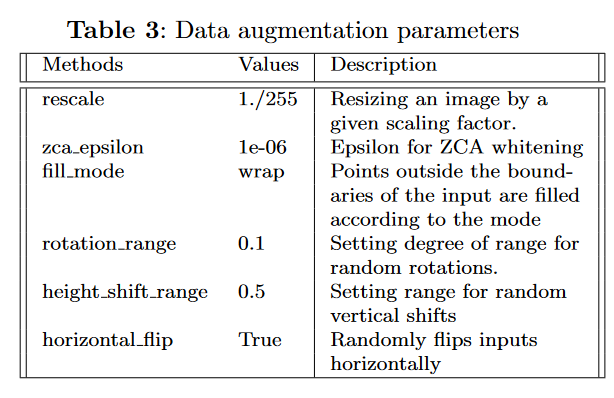
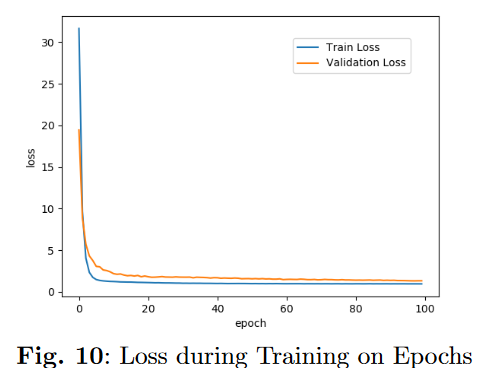
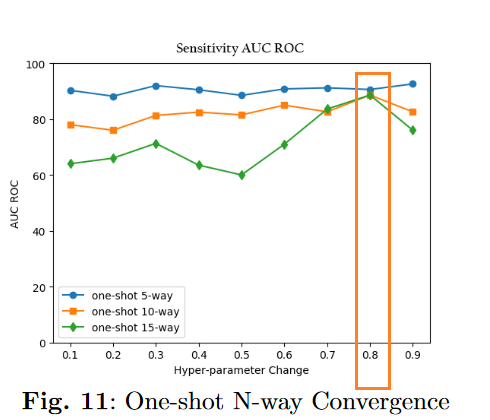
结果
1.训练阶段的损失变化
2.超参数调参
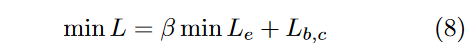
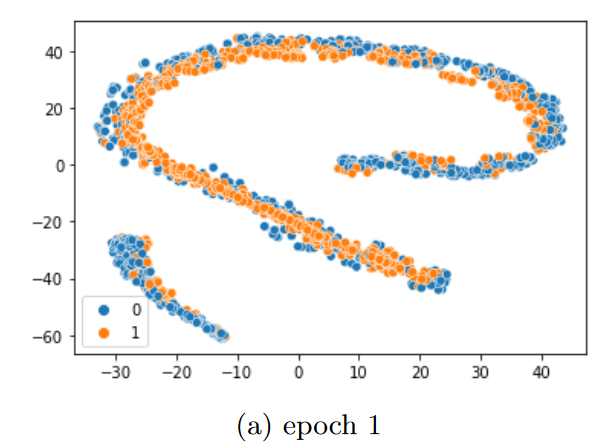
3.嵌入空间映射表示
二维主成分分析,实现训练结果的可视化。
 |
 |
基于HTML实现的图片并排
训练后,样本对几乎完全被区分开来。
4.本文的准确率比benchmark更好。
1-shot 5-way 10-way 15-way

5-shot 5-way 10-way 15-way

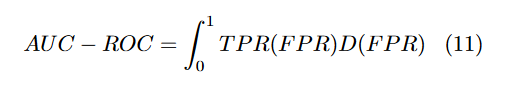
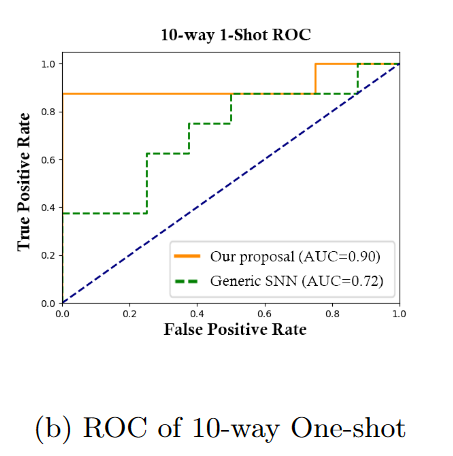
5.本文的AUC-ROC面积比通用的SNN更大。
先前工作的缺点:
小样本学习
先前的小样本学习工作只学习到 语义特征嵌入,并且,这些语义描述并不清晰,很难理解这些信息是如何被用于特征嵌入的。
过去:基于对比损失,或 没有考虑正类和负类之间的距离 -> 无法缩小类内方差intra-class variance,缩小同类距离。
改进:正负样本对必须被超平面有效区分开。—->混合损失—->同时改善类内方差,正负样本对间隔,扩大类间的距离。
特征嵌入
之前的模型倾向于捕获到恶意软件家族里明显的共有特征,一个家族的特有行为倾向于被视为噪声,却不能捕获特征的细微差异,而这正是发现混淆变体的的关键。
本文关注的控制流混淆的类型
功能不变,语义不变,但是编译出来的形式改变。
1.函数逻辑打乱 例如:code_fragment1->code_fragment2->code_fragment3,变为code_fragment1->code_fragment3->code_fragment2.
2.插入垃圾代码
3.函数分割 将一个函数分成片放入控制流中。
问题1:混合损失?
Center loss
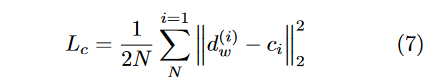
找到类的中心样本,并尽可能将有相似特征的训练样本尽可能靠近样本中心。
中心损失没有把含有不相似特征的训练样本分离开。
改进:
度量学习,在包含正样本中心点和负样本中心点的联合嵌入表示上,靠近正图像对,远离负图像对。
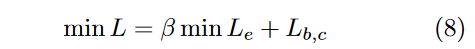
学习对比损失引起的过拟合的影响。
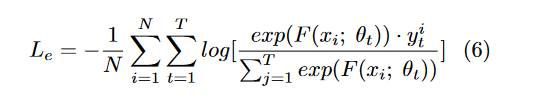
Lb,c表示中心损失的二元交叉熵损失
不改变特征空间中特征的属性。因此,该层的优化不会对网络更深的层产生负面影响。???
问题2:熵特征的引入有什么好处?
熵特征,衡量了给定程序的概率分布的不确定性,这个分布不受恶意软件函数逻辑顺序改变的影响,所以对于混淆软件有效。
字节概率分布不受控制流改变的影响。
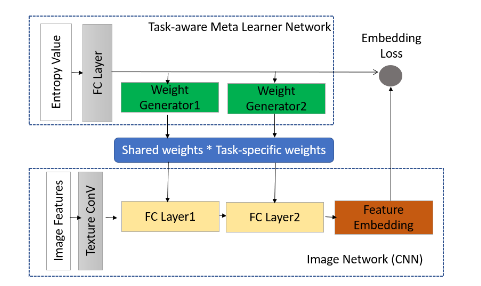
根据恶意软件家族特征调整CNN的特征嵌入权重:利用子网络1(基于熵特征的任务感知元学习网络) 确定 子网络2(图像分类网络)的权重参数。
所有的样本家族share一个高维的(m,n)的参数W-sr;对于每个家族,生成一个task-specific低维的参数Wts。
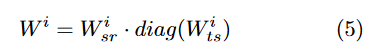
问题3:为什么图片尺寸设置为105?
wslubuntu的cuda安装
1.安装wsl子系统
1.安装如下的两个Windows功能,重启系统。
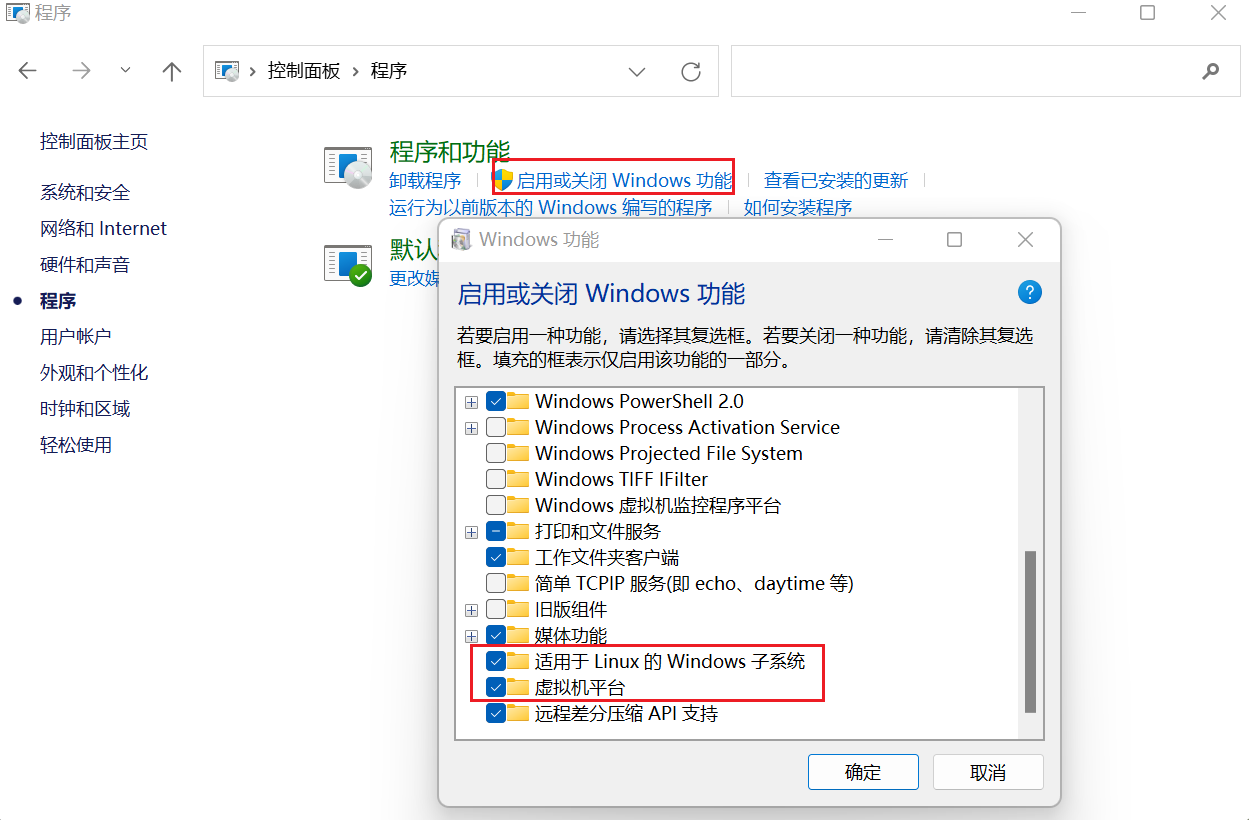
2.dos命令行,列出可以安装的子系统类型
1 | $:wsl -l -o |
3.下载Ubuntu18.04子系统
1 | wsl --install -d Ubuntu-18.04 |
2.在Windows上安装CUDA on WSL驱动
1.打开INVIDA-wsl驱动下载界面
2.输入你的配置,下载对应的驱动程序。
3.我下载的是这个
4.双击程序安装。
3.wsl安装cuda Toolkit
在dos命令行输入wsl,会自动启动之前安装的子系统。
在子系统的命令行里,一个一个执行下面的语句。
这里我使用了cuda11.3,因为pytorch官网目前给出的cuda版本有10.2,11.3,11.6.取最新版的前一版用就可以。
1 | #这里需要导入两个pubkey; |
4.安装Pytorch
1.下载conda。
在子系统的命令行里执行,安装Miniconda
1 | mkdir /home/$(whoami)/Downloads |
2.给conda建立软链接
1 | sudo ln -s /root/Miniconda3/bin/conda /usr/bin/conda |
3.下载cuda11.3版本的pytorch
1 | conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch |
5.验证安装是否成功
在子系统里执行下面的语句。
1 | #给root改名 |
diskpart
新建和隐藏分区符
1 | list disk |
wls子系统
1 | wsl --set-default-version 2 |
grub界面恢复到win11启动
1 | insmod part_gpt |
其他
1 | wsl --set-default-version 2 |
A Novel Few-Shot Malware Classification Approach for Unknown Family Recognition with Multi-Prototype Modeling
下载链接 用多原型模型做未知家族识别的全新小样本恶意代码分类方法
Peng Wang,《A Novel Few-Shot Malware Classification Approach for Unknown Family Recognition with Multi-Prototype Modeling》,Compyter&Securitty,April,2021.
1.问题
样本少,识别新家族需要重训练。
- scarce samples:新发现家族的样本收集困难,而用小批量样本,模型会过拟合,或者激烈振荡( oscillate drastically)不收敛;
- dynamic recognition:动态识别问题,旧分类器缺乏增量识别新家族的能力,要求从头开始重训练。
- signature-based analysis:需要专家设计签名,无法识别变形或者多态的样本(polymorphic or metamorphic)
- Open Set Recognition Problem (OSR)开放集识别问题,对新样本需要保持快速响应能力,从已经收集的样本中构建对应的分类器。
单模态方法和最近邻
概念
基础知识
多序列比对Multiple Sequence Alignment
方法
meta learning based few-shot learning (FSL)基于元学习的小样本学习
模型名:SIMPLE (Supervised Infifinite Mixture Prototypes LEarning)监督无限混合原型系统
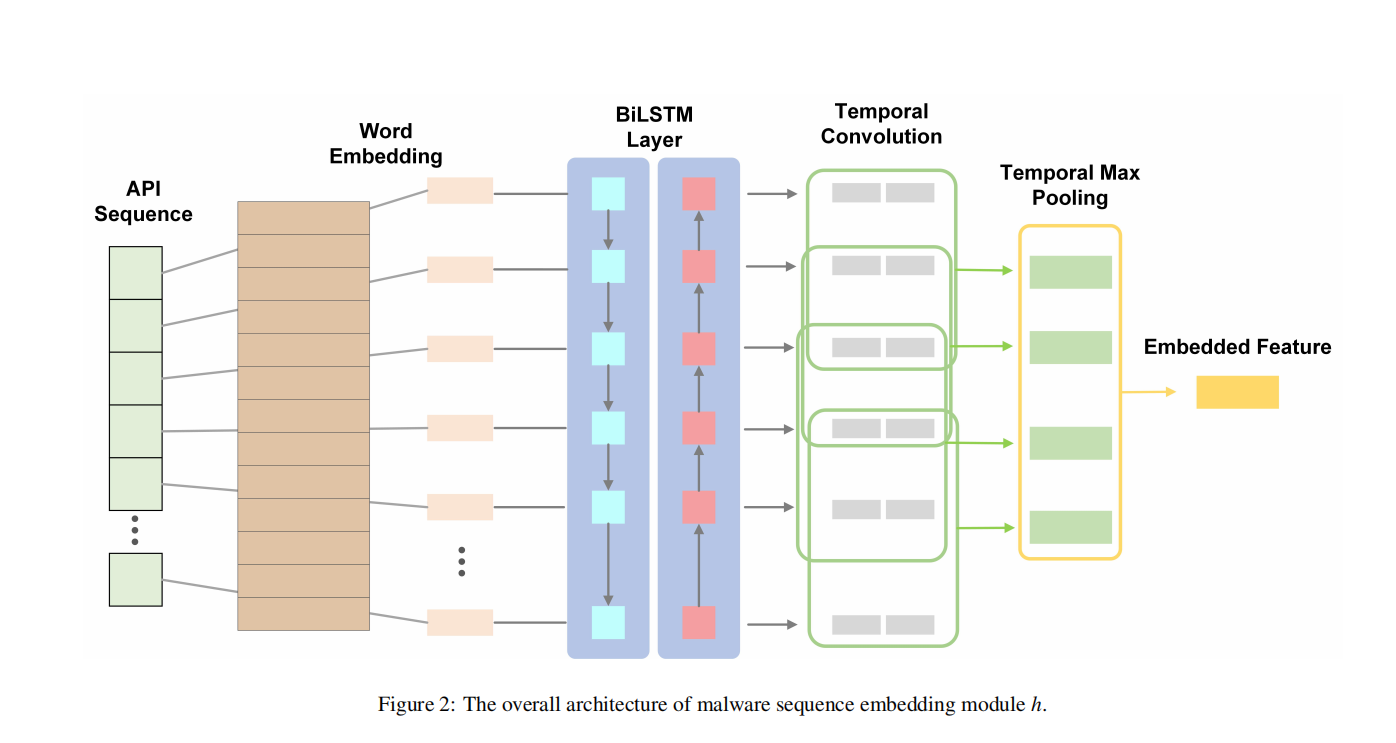
设计:基于从动态分析中获得的API调用序列(API invocation sequences),引入多原型建模来为每个家族生成多个原型。以增强泛化能力。
idea来源:同家族的行为有相同,也有不同,即经常会匹配多个子模式并满足多模态数据分布。
模型结构:
API invocation sequences—->word embedding—->LSTM(保留序列信息)——> clustering(聚类)—->每个恶意家族的多原型表示。
少量样本的监督标签信息
↓
无限混合原型IMP(infifinite mixture prototypes):聚类数目无需事先确定,模型容量能够根据任务数据自适应推断以平衡简单和复杂的数据分布。↓
更合理的恶意样本家族的原型